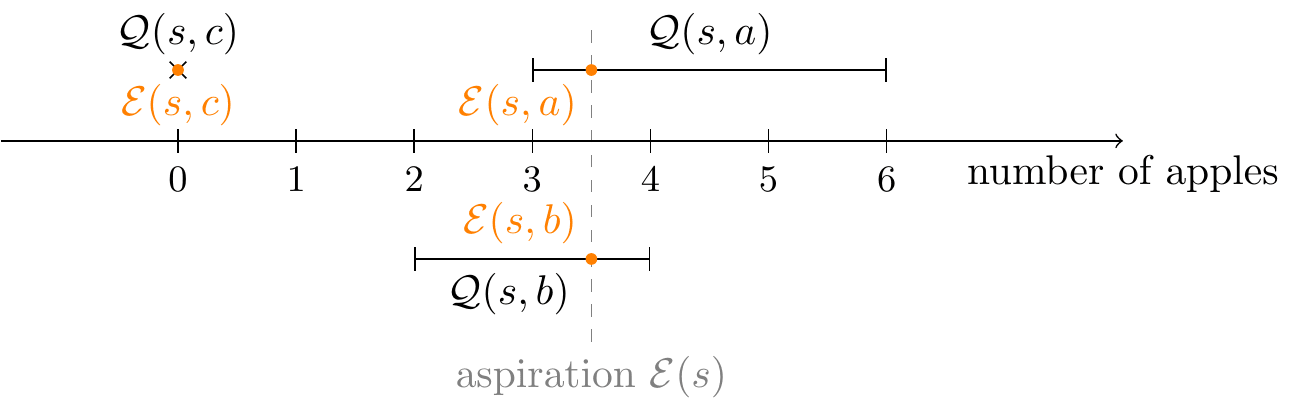Published on April 28, 2024 1:04 PM GMT
Summary. In this post, we extend the basic algorithm by adding criteria for choosing the two candidate actions the algorithm mixes, and by generalizing the goal from making the expected Total equal a particular value to making it fall into a particular interval. We only use simple illustrative examples of performance and safety criteria and reserve the discussion of more useful criteria for later posts.
Introduction: using the gained freedom to increase safety
After having introduced the basic structure of our decision algorithms in the last post, in this post we will focus on the core question: How shall we make use of the freedom gained from having aspiration-type goals rather than maximization goals?
After all, while there is typically only a single policy that maximize some objective function (or very few, more or less equivalent policies), there is typically a much larger set of policies that fulfill some constraints (such as the aspiration to make the expected Total equal some desired value).
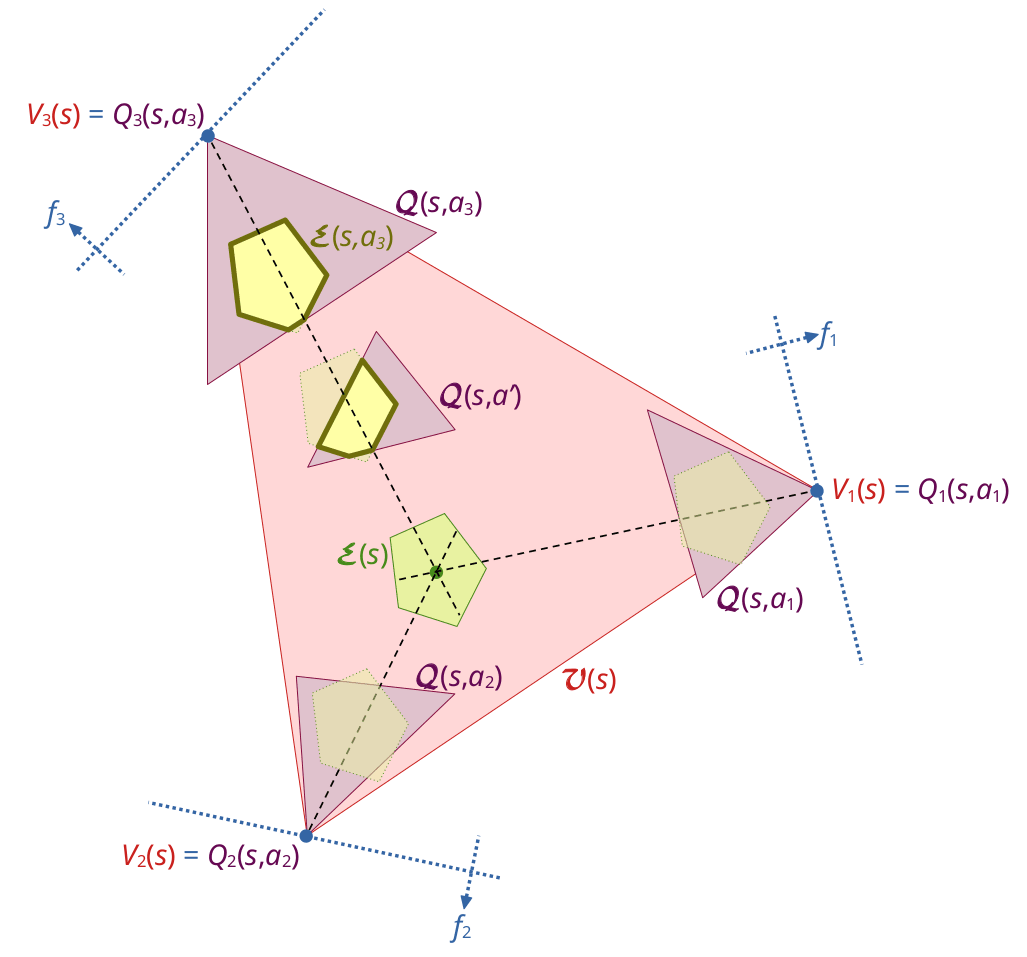
More formally: Let us think of the space of all (probabilistic) policies, Π, as a compact convex subset of a high-dimensional vector space with dimension d≫1 and Lebesgue measure μ. Let us call a policy π∈Π successful iff it fulfills the specified goal, G, and let ΠG⊆Π be the set of successful policies. Then this set has typically zero measure, μ(ΠG)=0, and low dimension, dim(ΠG)≪d, if the goal is a maximization goals, but it has large dimension, dim(ΠG)≈d, for most aspiration-type goals.
E.g., if the goal is to make expected Total equal an aspiration value, Eτ=E, we typically have dim(ΠG)=d−1 but still μ(ΠG)=0. At the end of this post, we discuss how the set of successful policies can be further enlarged by switching from aspiration values to aspiration intervals to encode goals, which makes the set have full dimension, dim(ΠG)=d, and positive measure, μ(ΠG)>0.
What does that mean? It means we have a lot of freedom to choose the actual policy π∈ΠG that the agent should use to fulfill an aspiration-type goal. We can try to use this freedom to choose policies that promise to be rather safe than unsafe according to some generic safety metric, similar to the impact metrics used in reward function regularization for maximizers.
Depending on the type of goal, we might also want to use this freedom to choose policies that fulfill the goal in a rather desirable than undesirable way according to some goal-related performance metric.
In this post, we will illustrate this with only very few, "toy" safety metrics, and one rather simple goal-related performance metric, to exemplify how such metrics might be used in our framework. In a later post, we will then discuss more sophisticated and hopefully more useful safety metrics.
Let us begin with a simple goal-related performance metric since that is the most straightforward.
Simple example of a goal-related performance metric
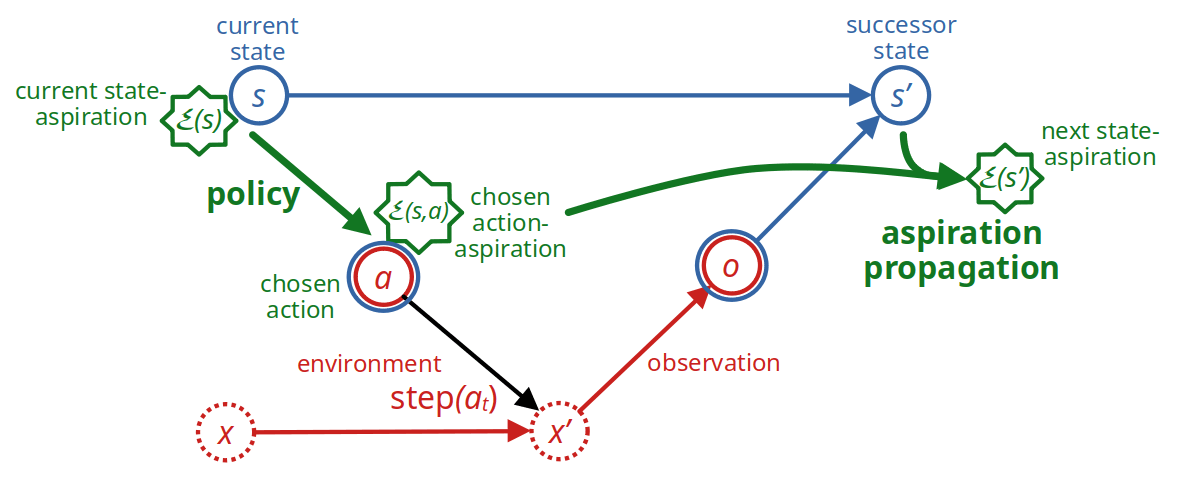
Recall that in step 2 of the basic algorithm, we could make the agent pick any action a− whose action-aspiration is at most as large as the current state-aspiration, E(s,a−)≤E(s), and it can also pick any other action, a+, whose action-aspiration is at least as large as the current state-aspiration, E(s,a+)≥E(s). This flexibility is because in steps 3 and 4 of the algorithm, the agent is still able to randomize between these two actions a−,a+ in a way that makes expected Total, Eτ, become exactly E(s).
If one had an optimization mindset, one might immediately get the idea to not only match the desired expectation for the Total, but also to minimize the variability of the Total, as measured by some suitable statistic such as its variance. In a sequential decision making situation like an MDP, estimating the variance of the Total requires a recursive calculation that anticipates future actions, which can be done but is not trivial. We reserve this for a later post.
Let us instead look at a simpler metric to illustrate the basic approach: the (relative, one-step) squared deviation of aspiration, which is very easy to compute:
SDA(s,a):=(E(s,a)−E(s))2(¯¯¯¯V(s)−V––(s))2∈[0,1].The rationale for this is that at any time, the action aspirations E(s,a±) are the expected values of Total-to-go conditional on taking action a±, so keeping them close to E(s) will tend to lead to a smaller variance. Indeed, that variance is lower bounded by (E(s,a−)−E(s))2:p:(E(s,a+)−E(s))2, where p is the probability for choosing a+ calculated in step 3 of Algorithm 1.
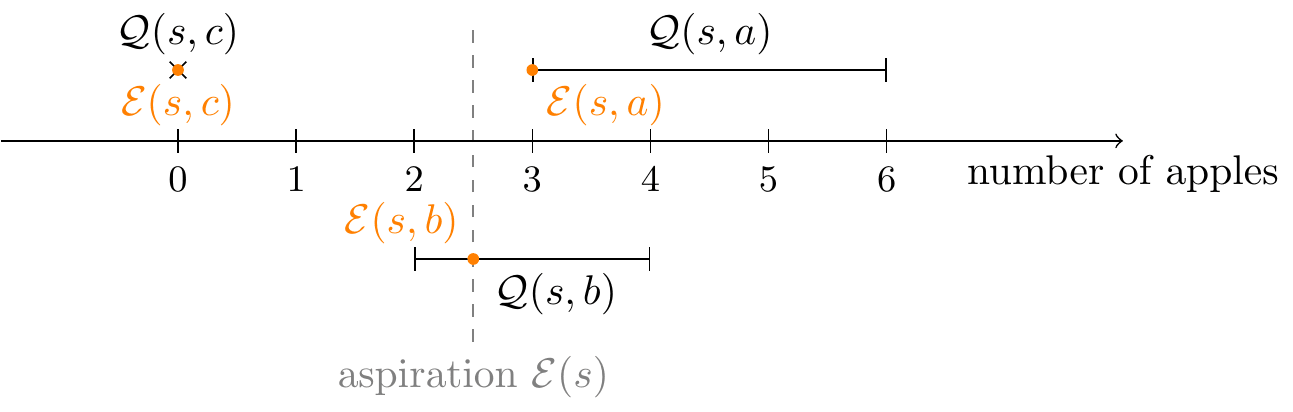
If the action space is rich enough, there will often be at least one action the action-aspiration of which equals the state-aspiration, E(s,a)=E(s), because the state-aspiration is contained in that action's feasibility interval, E(s)∈Q(s,a). There might even be a large number of such actions. This will in particular be the case in the early steps of an episode. This is because often one can distribute the amount of effort spent on a task more or less flexibly over time; as long as there is enough time left, one might start by exerting little effort and then make up for this in later steps, or begin with a lot of effort and then relax later.
If this is the case, then minimizing SDA(s,a) simply means choosing one of the actions for which E(s)∈Q(s,a) and thus E(s,a)=E(s) and thus SDA(s,a)=0, and then put a−=a+=a. When there are many such candidate actions a, that will still leave us with some remaining freedom for incorporating some other safety criteria to choose between them, maybe deterministically. One might thus think that this form of optimization is safe enough and should be performed because it gets rid of all variability and randomization in that step.
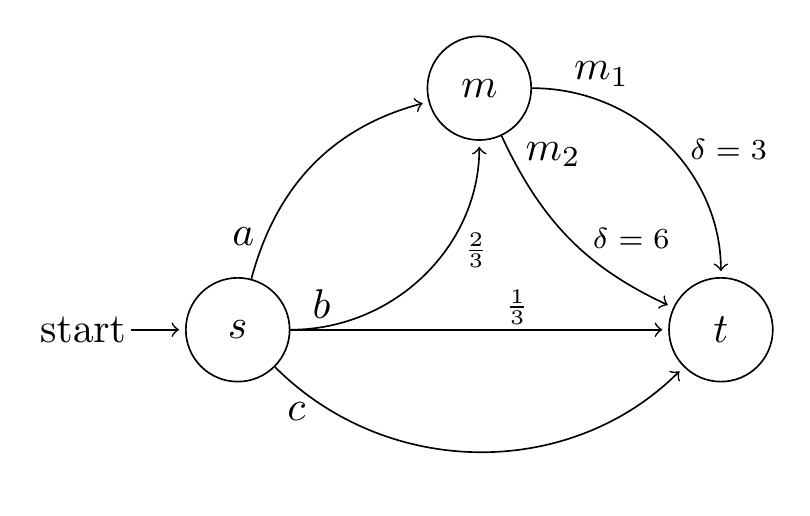
For example: Assume the goal is to get back home with fourteen apples within a week, and the agent can harvest or eat at most six apples on each day (apples are really scarce). Then each day the agent might choose to harvest or eat any number of apples, as long as its current stock of apples does not deviate from fourteen by more than six times the remaining number of days. Only in the last several days it might then have to harvest or eat exactly six apples per day, to make up for earlier deviations and to land at fourteen apples sharp eventually.
But there's at least two objections to minimizing SDA. First, generically, we can not be sure enough that there will indeed be many different actions for which E(s)∈Q(s,a), and so restricting our choice to the potentially only few actions that fulfill this might not allow us to incorporate safety criteria to a sufficient level. In particular, we should expect that the latter is often the case in the final steps of an episode, where there might at best be a single such action that perfectly makes up for the earlier under- or over-achievements, or even no such action at all. Second, getting rid of all randomization goes against the intuition of some many members of our project team that randomization is a desirable feature that tends to increase rather than decrease safety (this intuition also underlies the alternative approach of quantilization).
We think that one should thus not minimize performance metrics such as SDA or any other of the later discussed metrics, but at best use them as soft criteria. Arguably the most standard way to do this is to use a softmin (Boltzmann) policy for drawing both candidate actions a− and a+ independently of each other, on the basis of their SDA (or another metric's) scores:
a±∼exp(−β×SDA(s,a±))restricted to those a−,a+ with Q(s,a−)≤Q(s)≤Q(s,a+), and for some sufficiently small inverse temperature β>0 to ensure sufficient randomization.
While the SDA criterion is about keeping the variance of the Total rather low and is thus about fulfilling the goal in a presumably more desirable way from the viewpoint of the goal-setting client, the more important type of action selection criterion is not goal- but safety-related. So let us now look at the latter type of criterion.
Toy example of a generic safety metric
As the apple example above shows, the agent might easily get into a situation where it seems to be a good idea to take an extreme action. A very coarse but straightforward and cheap to compute heuristic for detecting at least some forms of extreme actions is when the corresponding aspiration is close to an extreme value of the feasibility interval: E(s,a)≈Q––(s,a) or E(s,a)≈¯¯¯¯Q(s,a).
This motivates the following generic safety criterion, the (relative, one-step) squared extremity of aspiration:
SEA(s,a):=4×((Q––(s,a)∖E(s,a)∖¯¯¯¯Q(s,a))−1/2)2∈[0,1].(The factor 4 is for normalization only)
The rationale is that using actions a−,a+ with rather low values of SEA would tend to make the agent's aspirations stay close to the center of the relevant feasibility intervals, and thus hopefully also make its actions remain moderate in terms of the achieved Total.
Let's see whether that hope is justified by studying what minimizing SEA would lead to in the above apple example:
- On day zero, E(s0)=14, V(s)=[−42,42], and Q(s0,a)=[a−36,a+36] for a∈{−6,…,6}. Since the current state-aspiration, 14, is in all actions' feasibility intervals, all action-aspirations are also 14. Both the under- and overachieving action with smallest SEA is thus a−=a+=6, since this action's Q-midpoint, 6, is closest to its action-aspiration, 14. The corresponding λ=−30∖14∖42=44/72.
- On the next day, the new feasibility interval is V(s1)=[−36,36], so the new state-aspiration is E(s1)=−36:44/72:36=8. This is simply the difference between the previous state-aspiration, 14, and the received Delta, 6. (It is easy to see that the aspiration propagation mechanism used has this property whenever the environment is deterministic). Since Q(s1,a)=[a−30,a+30]∋8, we again have E(s1,a)=8 for all a, and thus again a−=a+=6 since 6 is closest to 8.
- On the next day, E(s2)=8−6=2, Q(s2,a)=[a−24,a+24]∋2, and now a−=a+=2 since 2 is closest to 2. Afterwards, the agent neither harvests not eats any apples but lies in the grass, relaxing.
The example shows that the consequence of minimizing SEA is not, as hoped, always an avoidance of extreme actions. Rather, the agent chooses the maximum action in the first two steps (which might or might not be what we eventually consider safe, but is certainly not what we hoped the criterion would prevent).
Maybe we should compare Deltas rather than aspirations if we want to avoid this? So what about (relative, one-step) squared extremity of Delta,
SED(s,a):=4×((mina′Eδ(s,a′)∖Eδ(s,a)∖maxa′Eδ(s,a′))−1/2)2∈[0,1],If the agent minimizes this instead of SEA in the apple example, it will procrastinate by choosing a−=a+=0 for the first several days, as long as 14∈Q(st,0)=[6t−36,36−6t]. This happens on the first four days. On the fifth day (t=4), it will still have aspiration 14. It will then again put a−=0 with action-aspirationE(s4,0)=12=¯¯¯¯Q(s4,0), but it will put a+=2 with action-aspiration E(s4,2)=14. Since the latter equals the state-aspiration, the calculated probability in step 3 of the algorithm turns out to be p=1, meaning the agent will use action a+ for sure after all, rather than randomizing it with a−. This leaves an aspiration of 14−2=12. On the remaining two days, the agent then has to use a=6 to fulfill the aspiration in expectation.
Huh? Even though both heuristics seem to be based on a similar idea, one of them leads to early extreme action and later relaxation, and the other to procrastination and later extreme action, just the opposite. Neither of them avoids extreme actions.
One might think that one could fix the problem by simply adding the two metrics up into a combined safety loss,
L(s,a):=SEA(s,a)+SED(s,a)∈[0,2].But in the apple example, the agent would still harvest six apples on the first day, since (14−6)2+(6−0)2<(14−5)2+(5−0)2. Only on the second day, it would harvest just four instead of six apples, because (8−4)2+(4−0)2 is minimal. On the third day: two apples because (4−2)2−(2−0)2 is minimal. Then one apple, and then randomize between one or zero apples, until it has the 14 apples, or until the last day has come where it needs to harvest one last apple.
The main reason for all these heuristics failing in that example is their one-step nature which does not anticipate later actions. In a later post we will thus study more complex, farsighted metrics that can still be computed efficiently in a recursive manner, such as disordering potential,
DP(s,a)=Es′|s,a(−logP(s′|s,a)+log∑aexp(DP(s,a))),which measures the largest Shannon entropy in the state trajectory that the agent could cause if it aimed to, or terminal state distance,
TSD(s,a,E(s,a))=Es′|s,a(1s′ is terminald(s′,s0)+1s′ is not terminalEa′∼π(s′,E(s′))TSD(s′,a′,E(s′,a′))),which measures the expected distance between the terminal and initial state according to some metric d on state space and depends on the actual policy π and aspiration propagation scheme E(s)→E(s,a)→E(s′) that the agent uses.
But before looking at such metrics more closely, let us finish this post by discussing other ways to combine several performance and/or safety metrics.
Using several safety and performance metrics
Defining a combined loss function like L(s,a) above by adding up components is clearly not the only way to combine several safety and/or performance metrics, and is maybe not the best way to do that because it allows unlimited trade-offs between the components.
It also requires them to be measured in the same units and to be of similar scale, or to make them so by multiplying them with suitable prefactors that would have to be justified. This at least can always be achieved by some form of normalization, like we did above to make SEA and SED dimensionless and bounded by [0,1].
Trade-offs between several normalized loss components Li(s,a)∈[0,1] can be limited in all kinds of ways, for example by using some form of economics-inspired "safety production function" such as the CES-type function
L(s,a)=1−(∑ibi(1−Li(s,a))ρ)1/ρwith suitable parameters ρ and bi>0 with ∑ibi=1. For ρ=1, we just have a linear combination that allows for unlimited trade-offs. At the other extreme, in the limit of ρ→−∞, we get L(s,a)=maxiLi(s,a), which does not allow for any trade-offs.
Such a combined loss function can then be used to determine the two actions a−,a+, e.g., using a softmin policy as suggested above.
An alternative to this approach is to use some kind of filtering approach to prevent unwanted trade-offs. E.g., one could use one of the safety loss metrics, L1(s,a), to restrict the set of candidate actions to those with sufficiently small loss, say withL1(s,a)≤mina′L1(s,a′):0.1:maxa′L1(s,a′), then use a second metric, L2, to filter further, and so on, and finally use the last metric, Lk, in a softmin policy.
As we will see in a later post, one can come up with many plausible generic safety criteria, and one might be tempted to just combine them all in one of these ways, in the hope to thereby have found the ultimate safety loss function or filtering scheme. But it might also well be that one will have forgotten some safety aspects and end up with an imperfect combined safety metric. This would be just another example of a misspecified objective function. Hence we should again resist falling into the optimization trap of strictly minimizing that combined loss function, or the final loss function of the filtering scheme. Rather, the agent should probably still use a sufficient amount of randomization in the end, for example by using a softmin policy with sufficient temperature.
If it is unclear what a sufficient temperature is, one can set the temperature automatically so that the odds ratio between the least and most likely actions equals a specified value: β:=η/(maxaL(s,a)−minaL(s,a)) for some fixed η>0.
More freedom via aspiration intervals
We saw earlier that if the goal is to make expected Total equal an aspiration value, Eτ=E∈R, the set of successful policies has large but not full dimension and thus still has measure zero. In other words, making expected Total exactly equal to some value still requires policies that are very "precise" and in this regard very "special" and potentially dangerous. So we should probably allow some leeway, which should not make any difference in almost all real-world tasks but increase safety further by avoiding solutions that are too special.
Of course the simplest way to provide this leeway would be to just get rid of the hard constraint altogether and replace it by a soft incentive to make Eτ close to E∈R, for example by using a softmin policy based on the mean squared error. This might be acceptable for some tasks but less so for others. The situation appears to be somewhat similar to the question of choosing estimators in statistics (e.g., a suitable estimator of variance), where sometimes one only wants the estimator with the smallest standard error, not caring for bias (and thus not having any guarantee about the expected value), sometimes one wants an unbiased estimator (i.e., an estimator that comes with an exact guarantee about the expected value), and sometimes one wants at least a consistent estimator that is unbiased in the limit of large data and only approximately unbiased otherwise (i.e., have only an asymptotic rather than an exact guarantee about the expected value).
For tasks where one wants at least some guarantee about the expected Total, one can replace the aspiration value by an aspiration interval E=[e–,¯¯¯e]⊆R and require that Eτ∈E.
The basic algorithm (algorithm 1) can easily be generalized to this case and only becomes a little bit more complicated due to the involved interval arithmetic:
Decision algorithm 2
Similar to algorithm 1, we...
- set action-aspiration intervals E(s,a)=[e–(s,a),¯¯¯e(s,a)]⊆Q(s,a) for each possible action a∈A on the basis of the current state-aspiration interval E(s)=[e–(s),¯¯¯e(s)] and the action's feasibility interval Q(s,a), trying to keep E(s,a) similar to and no wider than E(s),
- choose an "under-achieving" action a− and an "over-achieving" action a+ w.r.t. the midpoints of the intervals E(s) and E(s,a),
- choose probabilistically between a− and a+ with suitable probabilities, and
- propagate the action-aspiration interval E(s,a) to the new state-aspiration interval E(s′) by rescaling between the feasibility intervals of a and s′.
More precisely: Let m(I) denote the midpoint of interval I. Given state s and state-aspiration interval E(s),
- For all a∈A, let E(s,a) be the closest interval to E(s) that lies within Q(s,a) and is as wide as the smaller of E(s) and Q(s,a).
- Pick some a−,a+∈A with m(E(s,a−))≤m(E(s))≤m(E(s,a+))
- Compute p←m(E(s,a−))∖m(E(s))∖m(E(s,a−))
- With probability p, put a←a+, otherwise put a←a−
- Implement action a in the environment and observe successor state s′←step(s,a)
- Compute λ––←Q––(s,a)∖e–(s,a)∖¯¯¯¯Q(s,a) and e–(s′)←V––(s′):λ––:¯¯¯¯V(s′), and similarly for ¯¯¯λ and ¯¯¯e(s′)
Note that the condition that no E(s,a) must be wider than E(s) in step 1 ensures that, independently of what the value of p computed in step 3 will turn out to be, any convex combination q−:p:q+ of values q±∈E(s,a±) is an element of E(s). This is the crucial feature that ensures that aspirations will be met:
Theorem (Interval guarantee)
If the world model predicts state transition probabilities correctly and the episode-aspiration interval E(s0) is a subset of the initial state's feasibility interval, E(s0)⊆V(s0), then algorithm 2 fulfills the goal Eτ∈E(s0).
The Proof is completely analogous to the proof in the last post, except that each occurrence of V(s,e)=E(s)∈V(s) and Q(s,a,e)=E(s,a)∈Q(s,a) is replaced by V(s,e)∈E(s)⊆V(s) and Q(s,a,e)∈E(s,a)⊆Q(s,a), linear combination of sets is defined as cX+c′X′={cx+c′x′:x∈X,x′∈X′}, and we use the fact that m(E(s,a−)):p:m(E(s,a+))=m(E(s)) implies E(s,a−):p:E(s,a+)⊆E(s).
Special cases
Satisficing. The special case where the upper end of the aspiration interval coincides with the upper end of the feasibility interval leads to a form of satisficing guided by additional criteria.
Probability of ending in a desirable state. A subcase of satisficing is when all Deltas are 0 except for some terminal states where it is 1, indicating that a "desirable" terminal state has been reached. In that case, the lower bound of the aspiration interval is simply the minimum acceptable probability of ending in a desirable state.
Before discussing some more interesting safety metrics, we will first introduce in the next post a few simple environments to test these criteria in...
Discuss