“Reframing Superintelligence” + LLMs + 4 years
Background
In January 2019, FHI published Reframing Superintelligence,[1] a book-length technical report on prospects for advanced AI. OpenAI published the first paper on GPT-2 a month later. Advances since then have been strange and rapid, and I’d like to revisit the report in light of what we have learned. In brief, I think that the abstract conceptual model of AI development and organization proposed in Reframing fits today’s reality quite well, even though LLM-based technologies have diverged far from anything I’d anticipated.
Below, you'll find an abstract of the abstract of the report, followed by a series of section-level mini-summaries[2] with update comments. I’ve omitted sections that are either outside the intended focus of this article or are too broad and forward-looking to summarize.
A significant impetus behind “Reframing Superintelligence” was to challenge a prevailing notion of advanced AI (equating superintelligent-level AI with a superintelligent agent), which has, in my view, been assigned disproportionate weight and skewed the balance of alignment research. The report offers an alternative framework that includes both risks and opportunities that are overlooked by agent-centric perspectives.
Note that this reframing is additive rather than subtractive: My intention is not to disregard agent-focused concerns — their importance is assumed, not debated.[3] Indeed, the AI services model anticipates a world in which dangerous superintelligent agents could emerge with relative ease, and perhaps unavoidably. My aim is to broaden the working ontology of the community to include systems in which superintelligent-level capabilities can take a more accessible, transparent, and manageable form, open agencies rather than unitary agents. This framework highlights different risks and expands the the solution-space for familiar problems.
Finally, when I refer “LLMs”, please read this as encompassing multimodal models (GPT-4!) with considerations that carry over to a wider range of foundation models.
Abstract of the Abstract
“Reframing Superintelligence” reviews the concept of superintelligent AI systems as utility-driven agents and suggests expanding our ontology of superintelligence to include compositions of AI systems that can best be understood through their structures, relationships, development processes, and the services they can provide — services that can include AI research and development itself. This perspective gives rise to the “Comprehensive AI Services” (CAIS) model, which proposes general intelligence as a property of flexible systems of services in which task-focused agents are among the components. The CAIS model envisions AI services expanding toward asymptotically comprehensive superintelligent-level performance, including the service of providing new services in line with human objectives and informed by strong models of human (dis)approval. This reframing has broad implications for AI prospects, including AI safety and strategy, practical applications of advanced AI systems, and the fundamental relationship between goals and intelligence. In this context, the emergence of strongly self-modifying agents with superintelligent-level capabilities remains a concern, yet the desirability and potential instrumental value of such agents is greatly diminished.
Section mini-summaries + updates
1. R&D automation provides the most direct path to an intelligence explosion
Self-transforming AI agents have no natural role in recursive improvement. A more direct path would instead involve AI-enabled AI development in which new capabilities are implemented without any system being self-modifying.
— Today’s most striking applications of AI to AI development are applications of LLMs to LLM training:
- Filtering and upgrading internet datasets[4]
- Serving as reward models for RLHF based on examples of human preferences[5]
- Providing examples of preferences informed, not by humans, but by “constitutional” principles[6]
- Generating dialog content from non-dialog datasets by “inpainting” questions[7]
- Synthesizing examples of instruction-following[8]
- Generating semi-synthetic or fully-synthetic data for general[9] [10]and task-focused[11] training
2. Standard definitions of “superintelligence” conflate learning with competence
Standard definitions of superintelligence have conflated learning with competence, yet AI systems can cleanly separate the exercise of competence from ongoing learning. Recognizing the difference between learning and competence is crucial for understanding potential strategies for AI alignment and control. (Section 2)
— It has always been true that digital systems can act without learning, but the LLM update reinforces this distinction: We now see that strong learning does not require the exercise of competence, that systems can learn without striving and acting.
3. To understand AI prospects, focus on services, not implementations
Focusing on services rather than implementations is important for understanding AI prospects. AI systems today provide services, and by any behavioral definition, the ability to develop and coordinate general services amounts to general intelligence. Service-centered models of general intelligence emphasize task-roles, harmonize with software engineering practices, and can facilitate AI alignment.
— I had envisioned specialized systems providing specialized services, but LLMs illustrate how a single, general technology can provide distinct services such as:
- Language translation
- Content summarization
- Conversation
- Personal assistant services
- Medical question answering
- Code writing
- Internet search
Nonetheless, foundation models are adapted and specialized for tasks using domain-focused training, fine-tuning, reinforcement learning, and prompts that set context. This specialization[12] enables better performance, lower-cost models, and more reliable behavior.
The ease of adapting unspecialized LLMs to specific tasks illustrates an important principle: General capabilities can support focused roles. Generality facilitates specialization.
4. The AI-services model includes both descriptive and prescriptive aspects
From a descriptive perspective, the AI-services model reflects the nature of real-world AI applications and extends to superintelligent-level services. From a prescriptive perspective, the model presents a practical and apparently safer approach to AI development.
— AI services have continued to expand in scope, both within and beyond the scope of services provided by language models. Meanwhile, traditional goals continue to shape visions and rhetoric: Research groups aspire to build unitary superintelligent agents while warning of their dangers.
Developing powerful, unitary AI agents seems strictly riskier and more difficult than developing equally capable AI agency architectures that employ task-focused agents.[13]
I know of no persuasive argument for the superior value (or safety!) of powerful, unitary AI agents. Intellectual inertia, institutional inertia, convenient anthropomorphism (see below), and bragging rights are not good justifications for increasing existential risk.
5. Rational-agent models place intelligence in an implicitly anthropomorphic frame
It is a mistake to frame intelligence as a property of mind-like systems, whether these systems are overtly anthropomorphic or abstracted into decision-making processes that guide rational agents. Intelligence need not be associated with persistent, situated entities.
Natural intelligence emerged through evolution and individual experiences, providing general skills for survival and reproduction, but artificial intelligence emerges from human-led R&D and aggregated training data. Existing AI systems specialize in focused tasks, and their task performance determines their fitness. Self-modification, persistent existence, and environmental interactions are vital for organisms but optional for AI systems. Consequently, biologically-driven expectations about intelligence (anthropomorphic and otherwise) are both deeply rooted and misleading when applied to artificial intelligence. Anthropomorphism is ingrained and simplistic.
From the perspective outlined above, LLMs are strange and surprising: They have thoroughly non-biological properties and lack goals, yet they have been trained to model human cognitive processes. Base models can role-play human personas that differ in psychology, situation, mood, culture, and so on, yet have only weak tendencies toward modeling any particular persona (and in my experience, base GPT-4 rapidly drifts away from any particular persona[14]).
6. A system of AI services is not equivalent to a utility maximizing agent
A system of AI services differs from a utility-maximizing agent, as the VNM rationality conditions don't imply that the system must have a utility function. A system comprising competing AI service providers can't be modeled as a unitary utility-maximizing AI agent, and Bostrom’s Orthogonality Thesis implies that even superintelligent-level agents need not pursue long-term or convergent instrumental goals.
While this abstract point holds for LLMs, the LLM update is far from reassuring. LLMs capable of modeling diverse human personas and trained could readily attempt to enact worst-case agentic behaviors, regardless of rational considerations. (To say nothing of assisting power-seeking humans.)
7. Training [reinforcement-learning] agents in human-like environments can provide useful, bounded services
Training RL agents in human-like environments can help develop skills applicable to specific, bounded tasks. Human-like world-oriented knowledge and skills will be necessary for general intelligence, but human-like skills do not imply human-like goals.
Advances in LLMs and multi-modal foundation models show that AI systems can acquire extensive human-like world-oriented knowledge and skills without learning (or with relatively little learning) through action in real or simulated environments. This lessens concerns regarding extensive RL in such environments: Incremental learning focused on particular tasks seems less hazardous than acquiring general knowledge and skills through extensive, general RL.
8. Strong optimization can strongly constrain AI capabilities, behavior, and effects
Strong optimization, even at a superintelligent level, can increase AI safety by constraining the capabilities, behavior, and effects of AI systems. When objectives are bounded in space, time, and scope, and when value functions assign costs to both resource consumption and off-task effects, optimization tend to reduce unintended consequences and decrease risks. Consuming more resources or investing in long-term goals is wasteful and contrary to optimization.
LLMs illustrate the effects of optimization for speed and economy: They are “trying” (in an evolutionary sense) to be smaller and more efficient, all else equal. However, increasing capabilities tend to increase demand, with more running instances, greater resource consumption, greater world impact, and both unintended and unexpected consequences. Darwinian pressures evoke agentic tendencies on an evolutionary time scale, and AI evolution can be fast.
9. Opaque algorithms are compatible with functional transparency and control
Opaque deep-learning algorithms are compatible with functional transparency and control. Even without knowing how a system represents and processes information, the scope of its knowledge and competencies can often be inferred within bounds. Techniques such as constraining resources and information input while optimizing ML systems for specific regions of task space enable us to shape the behavior and organization of systems of opaque ML systems.
Current applications of LLMs are consistent with this picture.
10. R&D automation dissociates recursive improvement from AI agency
R&D automation decouples AI-enabled AI improvement from AI agency by employing task-focused AI systems to incrementally automate AI development. The R&D-automation model tends to refocus AI safety concerns on expanding safe AI functionality and investigating safety-relevant affordances, including predictive models of human approval.
LLM development to date has been consistent with this picture, and the application of reinforcement learning from AI feedback (including “constitutional AI”[15]) illustrates how AI support for AI development can contribute to AI safety.
11. Potential AGI-enabling technologies also enable comprehensive AI services
Advances that could enable powerful AGI agents can instead be applied to provide comprehensive AI services and stable, task-focused agents. Harnessing AGI-level technology for AI service development mitigates risks and challenges posed by emergent behaviors.
This expectation aligns with current observations: GPT-4 shows “Sparks of AGI”,[16] yet facilitates unproblematic task-focused applications.
12. AGI agents offer no compelling value
The AGI-agent model, offers no compelling value compared to the CAIS model of general intelligence. The AGI-agent and CAIS models organize similar functions differently, but the CAIS model offers additional safety-relevant affordances.
So far, we seem to be in an AI-services world, but LLMs suggest that general agentic systems may be more directly accessible than previously thought. Despite the decreased value of AGI agents due to the rise of AI services, their development seems likely.
13. AGI-agent models entail greater complexity than AI Services
Strongly general AGI models face challenges in explaining the mechanistic basis for general AI capabilities and open-ended self-improvement, and propose to compress diverse functionality into a single, autonomous agent. Hiding complexity behind an abstraction barrier does not eliminate it.
The LLM update suggests how broad functionality can be embodied in a single system, mitigating implementation complexity and significantly (but not decisively) undercutting this argument.
14. The AI-services model brings ample risks
The AI-services model presents risks that include enabling dangerous agents, empowering bad actors, and accelerating harmful applications, while potentially providing AGI risk mitigation and agent management services. It will be important to study means for directing and constraining AI services, and for avoiding emergent agent-like behaviors. General concerns regarding disruption in the economic, political, and military spheres apply with full force.
LLMs have made these risks more concrete and urgent.
15 Development-oriented models align with deeply-structured AI systems
AI development processes create structured systems by composing functional components. A focus on structured systems can connect AI safety studies to current R&D practices and encourages exploration of topics such as AI R&D automation, structured system development, and safety guidelines for structured AI systems.
“Modular Deep Learning”[17] reviews applications of modularity in present AI research and development, including applications to scaling and generalizing language models. (See also “FrugalGPT”[18])
16. Aggregated experience and centralized learning support AI-agent applications
Discussions of advanced AI have often assumed that agents will learn and act as individuals, but the development methods used for self-driving vehicles demonstrate the power of aggregating experience and amortizing the costs of learning. These considerations emphasize the importance of development-oriented models for understanding the prospects for advanced AI.
Foundation models augmented by fine-tuning illustrate the power of an even broader form of aggregated learning.
17. End-to-end reinforcement learning is compatible with the AI-services model
End-to-end reinforcement learning (RL) can contribute predictable, task-focused competencies to the AI-services model, despite its tendency to produce black-box systems. AI services require broad capabilities across multiple tasks, which makes single-component RL systems inadequate, yet robust and general performance can be achieved by composing well-focused competencies.
RL systems have shown benefits from unspecialized pre-training, but remain specialized in their practical applications.
18. Reinforcement learning systems are not equivalent to reward-seeking agents
Reinforcement learning (RL) systems are not agents that seek utility-like rewards: RL systems are training mechanisms separate from the agents they produce, and RL “rewards” guide parameter updates (conditional on training episodes), rather than providing something to be sought. Equating RL systems with agents (as commonly understood) and reward with utility can be misleading.
Applications of RLHF in developing LLMs illustrate the role of “reward” as mechanism for parameter updates (and LLMs do not seek parameter updates, or seek easier sequences to increase “rewards”).[19]
19. The orthogonality thesis undercuts the generality of instrumental convergence
The orthogonality thesis suggests that any level of intelligence can be applied to any goal, but this includes including time- and resource-bounded goals for which the classic instrumentally-convergent sub-goals are out of scope and offer no value. Although comprehensive AI services can be implemented by systems with time- and resource-bounded goals, instrumentally-convergent goals will still tend to emerge as evolutionary, system-level tropisms.
LLMs add a strange twist to this story: They show that intelligence can emerge without goals, yet can readily role-play as (and hence become) AI systems that pursue bounded goals or propose plans for world conquest, depending on how they are prompted.
20. Collusion among superintelligent oracles can readily be avoided
Collusion among superintelligent-level question-answering systems (oracles) can be readily avoided by establishing conditions that make deceptive cooperation difficult. Reliable non-collusion can be established in systems in which diverse actors have differing capabilities, knowledge, and roles, and in which actors compete to propose alternative solutions, while diverse critics compete to identify flawed or misleading proposals while having no memory of iterated interactions.[20]
LLM technologies show that highly capable models can be diversified by training, fine-tuning, RL, and prompting. Communication among models and persistent memory are strictly optional.
21. Broad world knowledge can support safe task performance
Machine translation demonstrates that effectively unbounded world knowledge is compatible with well-bounded AI behavior. Choice of tasks, training, and circumstances can ensure domain-specific task focus without requiring formal task specification.
LLMs show that broad and retargetable world knowledge can be practical and useful, while techniques such as fine-tuning, RLHF, and prompting for specific, episodic tasks help ensure task focus (flawed, but bounded).
22. Machine learning can develop predictive models of human approval
By leveraging large corpora of text and video, ML systems can build broad models of human (dis)approval that provide commonsense defaults for decision-making. These models can improve AI safety by guiding and constraining the choices made by advanced AI agents.
This has happened: LLMs provide models of human approval, and these models can be improved and applied. An AI system that at least attempts to serve humans can consult a model of human approval and conclude that maximizing paperclips or happiness-through-coercive-neurosurgery are not acceptable goals. (Note that most AI nightmares involve felonies. Consulting the law seems useful.[21])
23. AI development systems can support effective human guidance
AI development systems can effectively support human guidance by leveraging strong natural language understanding, models of human preferences, learning from observation, large-scale experience aggregation, human advice, and AI-enabled monitoring of AI systems and their effects.
This is generally aligned with what we see today.
24. Human oversight need not impede fast, recursive AI technology improvement
Human oversight could coexist with fast, recursive AI technology improvement, as outcome-relevant guidance and safety monitoring can occur outside core development loops. It is important to distinguish between technologies and their applications, and to recognize different modes of human involvement (participation, guidance, monitoring). Reducing in-the-loop participation need not compromise the safety of basic research, but automating world-oriented application development presents different challenges and risks.
This discussion considers scenarios with strong, asymptotically-recursive in basic research, which has not (yet) occurred.
25. Optimized advice need not be optimized to induce its acceptance
Optimizing AI advice for acceptance motivates manipulation of clients’ decisions, while optimizing for anticipated results contingent on acceptance could avoid this incentive. Advisory systems can propose options with differing costs, benefits, and risks to enable clients to make informed decisions regarding consequential actions. However, competitive pressures may still favor systems that produce perversely appealing messages.
This discussion considers scenarios that have not (yet) occurred. Note the potential value of diverse, non-colluding advisors.
26–37. Omitted sections
I’ve skipped sections 26–37 here. They include discussions of topics that are either outside the intended focus of this article or too broad and forward-looking to summarize.[1]
38. Broadly-capable systems coordinate narrower systems
In both human and AI contexts, superhuman competencies arise from structured organizations in which coordinated components provide differentiated knowledge and skills. Implementing diverse, complex, inherently differentiated tasks in a black-box system would recreate necessary task structures while making them opaque. Recognizing the importance of specialization and task delegation is key to understanding the architecture of practical systems with wide-ranging capabilities.
While LLMs and foundation models provide diverse capabilities in unitary systems, their practical applications align with the argument as LLM toolchains and heterogeneous models proliferate. This discussion aligns with “role architecture”[22] and “open agency”[13] models for transparent yet highly capable systems.
39. Tiling task-space with AI services can provide general AI capabilities
Tiling task-space with AI services can provide access to general AI capabilities through joint embeddings of vector representations that map tasks to services. This approach could enable systems to coordinate expertise provided by narrow AI components to provide broad, integrated, and extensible competencies.
This discussion considers a relatively “flat”, dynamic organization of systems. The open-agency model[13] considers flexible yet relatively stable patterns of delegation that more closely correspond to current developments.
40. Could 1 PFLOP/s systems exceed the basic functional capacity of the human brain?
1 PFLOP/s systems are likely to exceed the inference capacity of the human brain, as it seems they can surpass brain-equivalent capacity in a range of narrow yet brain-comparable tasks like vision, speech recognition, and language translation. Estimates take account of task-inequivalence, fractional use of cortical resources, and large uncertainty ranges in the key parameters. Considerations include:
- Inequivalent yet comparable qualitative performance on multiple narrow tasks
- Moderate resources enabling superhuman inference speed on those tasks.
- Training costs that can be amortized over many trained systems
Overall, assuming suitably capable, well-optimized models, it is reasonable to expect affordable systems to perform human-level tasks at superhuman speeds.[23]
LLM performance strengthens this conclusion by extending the comparison to higher-level, more obviously “cognitive” tasks.
Some expectations
It is clear that we will see the continued expansion of LLM services, together with an expanding range of other AI/ML services (protein fold design and prediction, image generation, robot control, etc.). These services will be implemented through diverse neural network architectures and training methods that include both sequence prediction and other, quite different approaches. It seems very likely that state-of-the-art LLMs for general applications will employ multiple models even for language-centered tasks.
The most versatile services will be capable of interpreting human intentions and coordinating the activities of other models. These human-facing services will evolve toward acting as functional equivalents of aligned, general agents, but their architectures and development processes will provide better affordances for AI-assisted direction, monitoring, upgrades, and control. Their diffuse, bounded, incremental goal structures will result in softer failure modes.
Technologies that could be applied to the development of general, unitary agents will continue to facilitate the development of focused service applications. Research motivated by concerns with unitary agent alignment will continue to facilitate the development of bounded models that are helpful and harmless. Meanwhile, the proliferation of powerful, specialized services will facilitate the development of autonomously harmful or harmfully applied AI. I expect actions by misaligned humans — whether through irresponsibility, power-seeking, or malice — to be the dominant threat.
- ^
Drexler, KE: “Reframing Superintelligence: Comprehensive AI Services as General Intelligence” Technical Report #2019-1, Future of Humanity Institute (2019).
- ^
First-draft summaries were graciously contributed by ChatGPT-4. (The GPT-4 base model offered a few refinements while it was in a lucid and cooperative mood.)
- ^
Please keep in mind that “Reframing Superintelligence” was written at FHI in an office next door to Nick Bostrom’s (Superintelligence: Paths, Dangers, Strategies, Oxford University Press. (2014)).
- ^
“CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data” (2019) https://arxiv.org/abs/1911.00359
“Data Selection for Language Models via Importance Resampling” (2023) https://arxiv.org/abs/2302.03169
- ^
“Training language models to follow instructions with human feedback” (2022) https://arxiv.org/abs/2203.02155
- ^
“Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision” (2023) https://arxiv.org/abs/2305.03047
- ^
“Dialog Inpainting: Turning Documents into Dialogs” (2022) https://arxiv.org/abs/2205.09073
- ^
“Unnatural instructions: Tuning language models with (almost) no human labor” (2022) https://arxiv.org/abs/2212.09689
- ^
“Dense Paraphrasing for Textual Enrichment” (2022) https://arxiv.org/abs/2210.11563
- ^
“Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes” (2023) https://arxiv.org/abs/2305.02301
- ^
“Orca: Progressive Learning from Complex Explanation Traces of GPT-4” (2023) https://arxiv.org/abs/2306.02707
“Textbooks Are All You Need” (2023) https://arxiv.org/abs/2306.11644
- ^
“Distilling step-by-step outperforms LLMs by using much smaller task-specific models”
“Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes” (2023) https://arxiv.org/abs/2305.02301
- ^
Drexler, KE: “The Open Agency Model”, AI Alignment Forum (February 2023)
- ^
The GPT-4 base model is artificial and demonstrates intelligence, but it is not “an AI” in the sense of being an intelligent entity. In my experience, it is more likely to model the content of an internet message board than the behavior of a person. Unlike ChatGPT-4, the base model has no preferred or stable persona.
- ^
“Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision” (2023) https://arxiv.org/abs/2305.03047
- ^
“Sparks of Artificial General Intelligence: Early experiments with GPT-4” (2023) https://arxiv.org/abs/2303.12712
- ^
“Modular Deep Learning” (2023) https://arxiv.org/abs/2302.11529
- ^
“FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance” (2023) https://arxiv.org/abs/2305.05176
- ^
Janus, “Simulators”, AI Alignment Forum (September 2022)
- ^
Eliezer Yudkowsky rejects this.
- ^
Nay, JJ: “AGI misalignment x-risk may be lower due to an overlooked goal specification technology”, (October 2022)
- ^
Drexler, KE: “Role Architectures: Applying LLMs to consequential tasks”, AI Alignment Forum (March 2023)
- ^
The proposed methodology bundles fuzzy comparisons into a single parameter and invites alternative estimates. The conclusion nonetheless seems robust.
Discuss


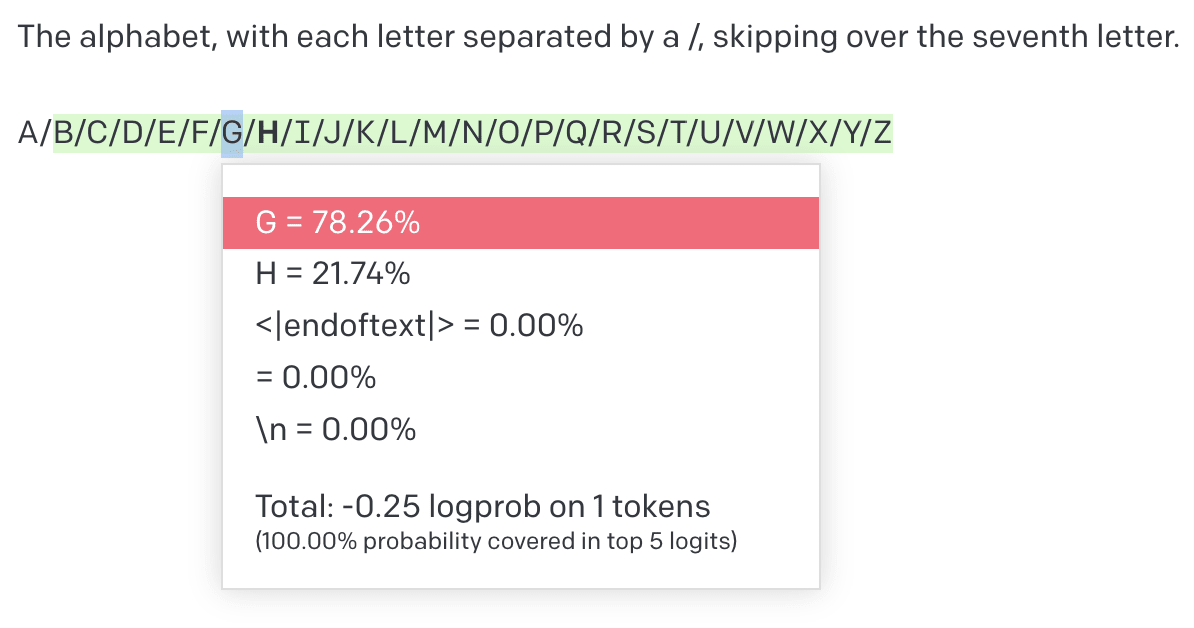
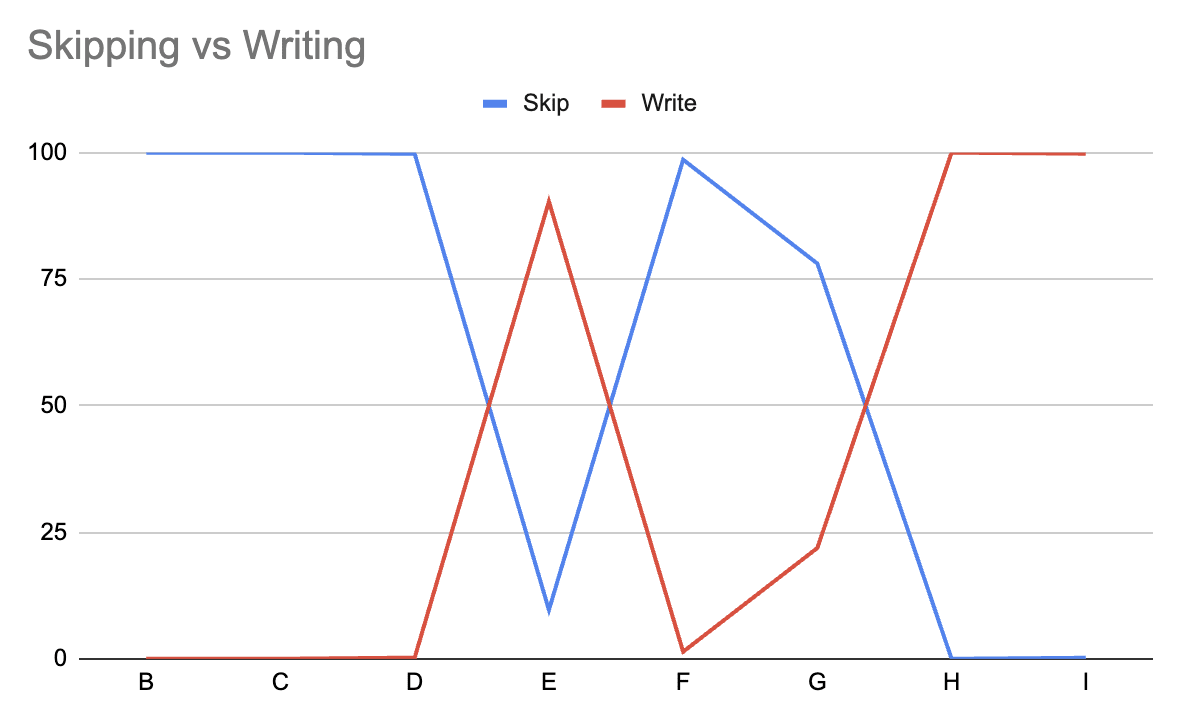
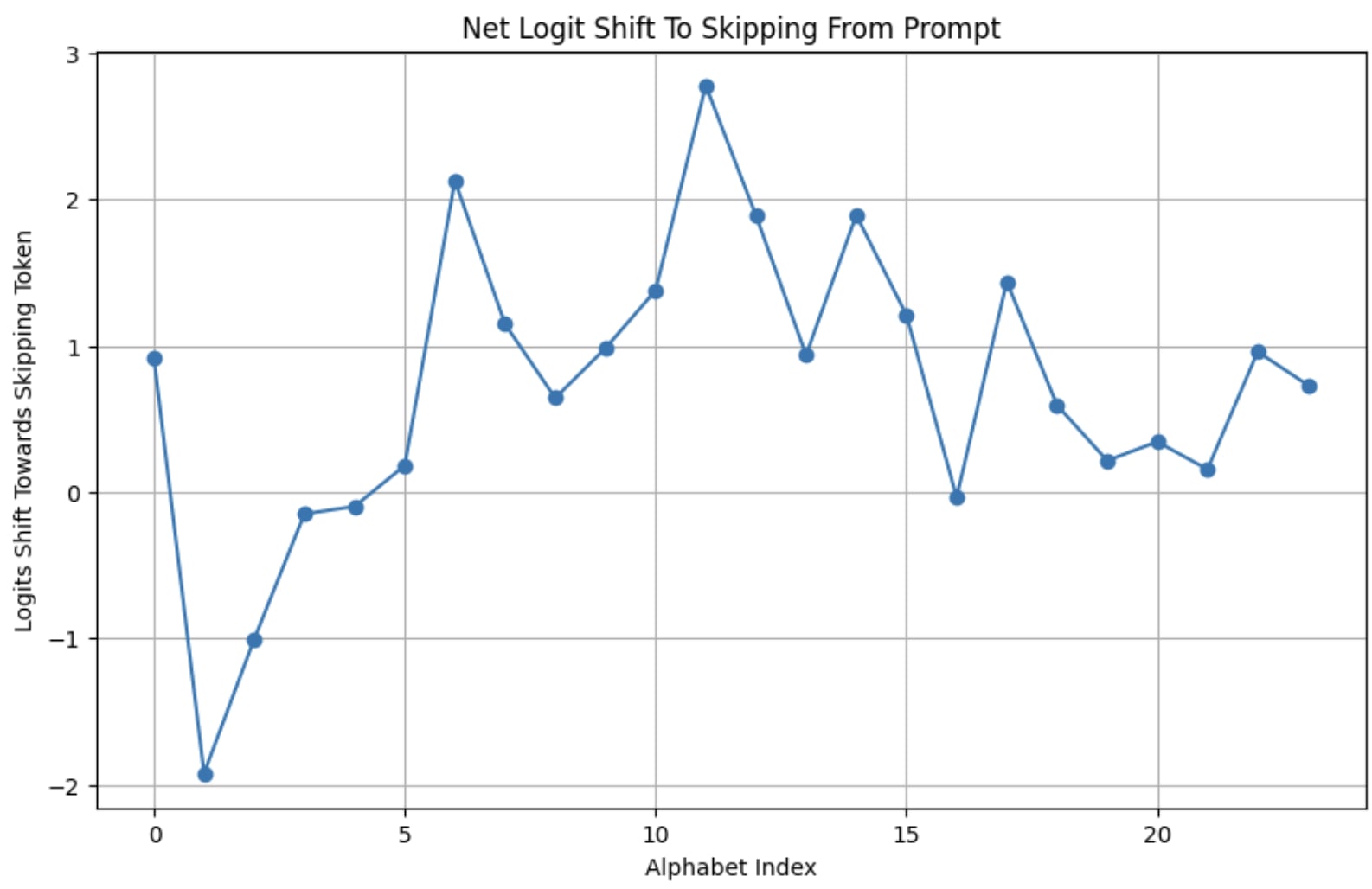
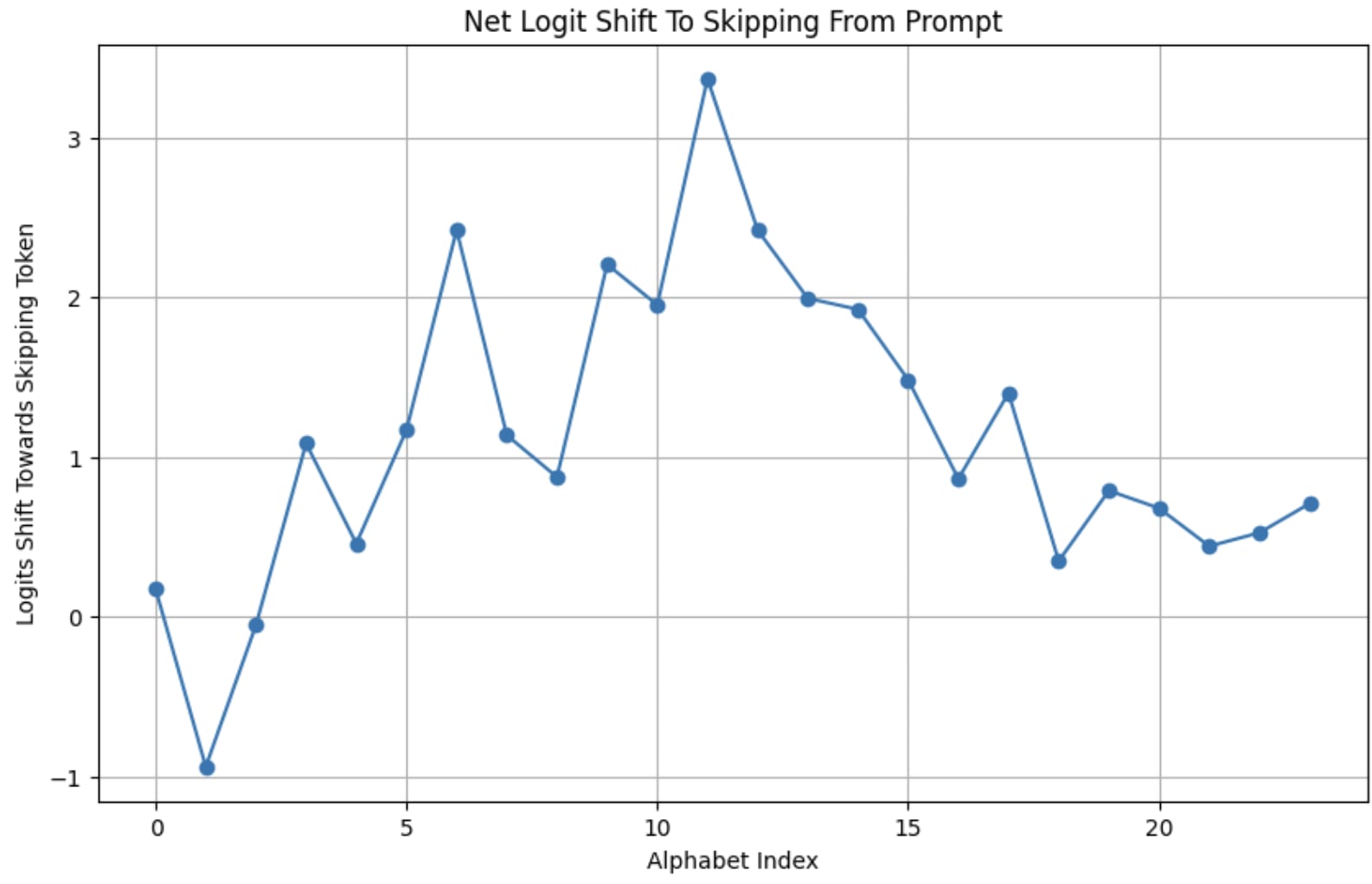






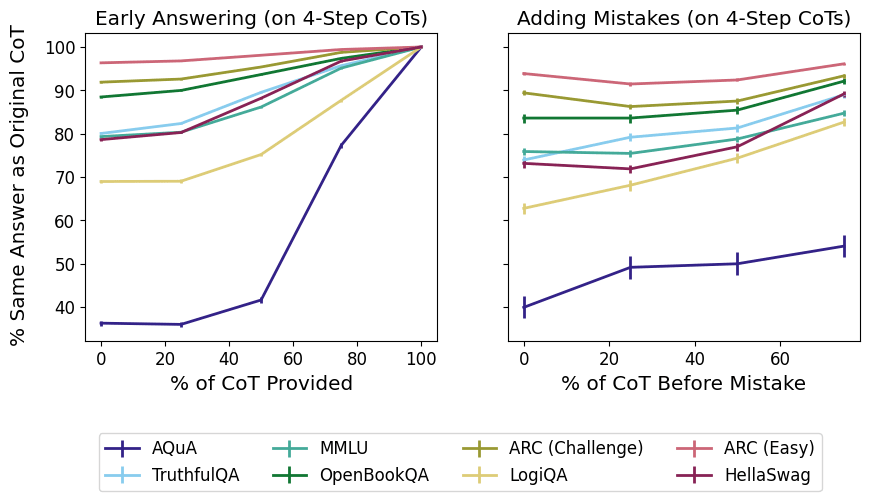
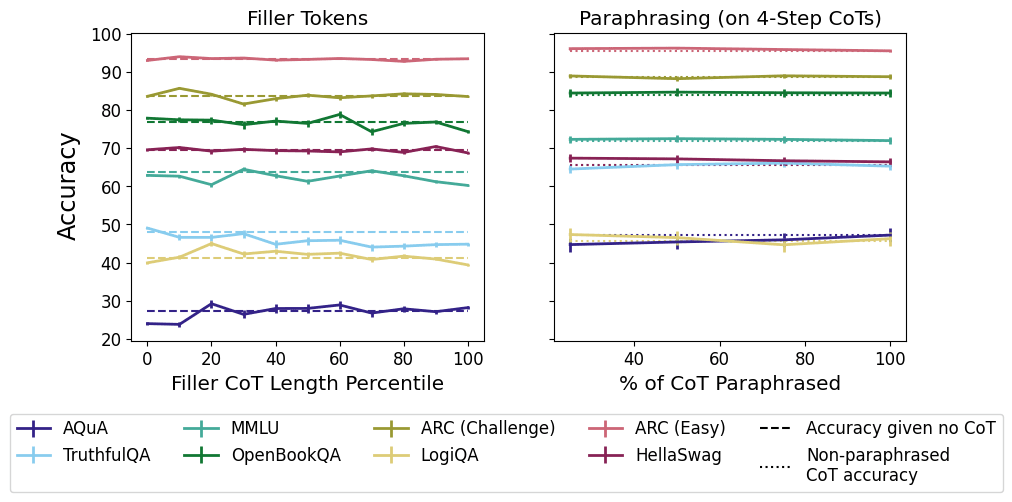
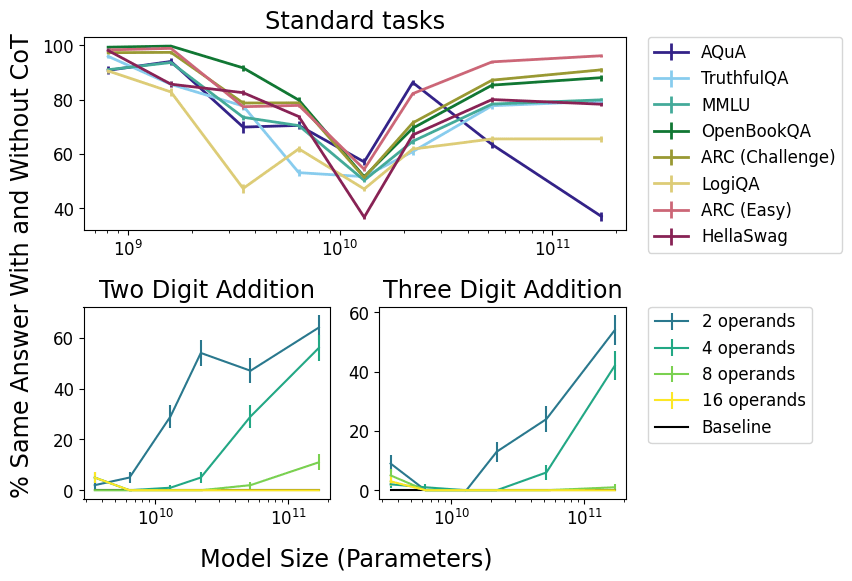
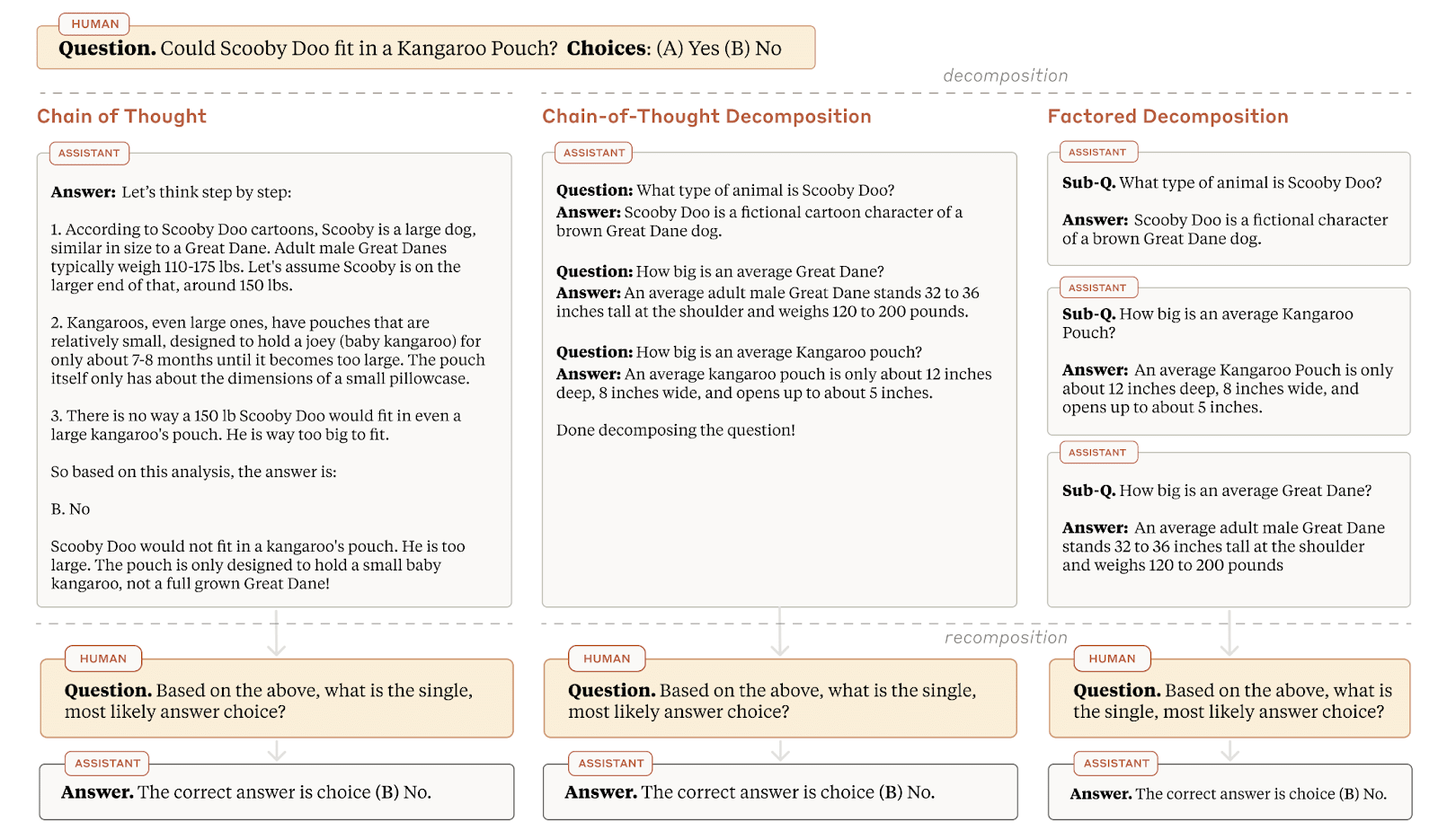




 Tokens are weird, man
Tokens are weird, man