One day after OpenAI showed off an all-new, emotional version of ChatGPT, the company announced that chief scientist Ilya Sutskever is leaving the company. He had voted in November to fire CEO Sam Altman.
Google is rethinking its most iconic and lucrative product by adding new AI features to search. One expert tells WIRED it’s “a change in the world order.”
Google's new voice-operated AI assistant, called Astra, can make sense of what your phone’s camera sees. It was announced one day after OpenAI revealed a similar vision for ChatGPT.
While the newest AI model from OpenAI, GPT-4o, is available to users for free, ChatGPT Plus subscribers still get access to more prompts and the newest features.
PauseAI protests are underway in London, New York, San Francisco, and across the globe. Its members have wildly different opinions on what the group should do next.
Prepare for ChatGPT to get more emotional. OpenAI demonstrated upgrades that make the chatbot capable of snappier conversations and showed the AI helper picking up on and expressing emotional cues.
Linked is my MSc thesis, where I do regret analysis for an infra-Bayesian[1] generalization of stochastic linear bandits.
The main significance that I see in this work is:
Expanding our understanding of infra-Bayesian regret bounds, and solidifying our confidence that infra-Bayesianism is a viable approach. Previously, the most interesting IB regret analysis we had was Tian et al which deals (essentially) with episodic infra-MDPs. My work here doesn't supersede Tian et al because it only talks about bandits (i.e. stateless infra-Bayesian laws), but it complements it because it deals with a parameteric hypothesis space (i.e. fits into the general theme in learning-theory that generalization bounds should scale with the dimension of the hypothesis class).
Discovering some surprising features of infra-Bayesian learning that have no analogues in classical theory. In particular, it turns out that affine credal sets (i.e. such that are closed w.r.t. arbitrary affine combinations of distributions and not just convex combinations) have better learning-theoretic properties, and the regret bound depends on additional parameters that don't appear in classical theory (the "generalized sine" S and the "generalized condition number" R). Credal sets defined using conditional probabilities (related to Armstrong's "model splinters") turn out to be well-behaved in terms of these parameters.
In addition to the open questions in the "summary" section, there is also a natural open question of extending these results to non-crisp infradistributions[2]. (I didn't mention it in the thesis because it requires too much additional context to motivate.)
I use the word "imprecise" rather than "infra-Bayesian" in the title, because the proposed algorithms achieves a regret bound which is worst-case over the hypothesis class, so it's not "Bayesian" in any non-trivial sense.
In particular, I suspect that there's a flavor of homogeneous ultradistributions for which the parameter S becomes unnecessary. Specifically, an affine ultradistribution can be thought of as the result of "take an affine subspace of the affine space of signed distributions, intersect it with the space of actual (positive) distributions, then take downwards closure into contributions to make it into a homogeneous ultradistribution". But we can also consider the alternative "take an affine subspace of the affine space of signed distributions, take downwards closure into signed contributions and then intersect it with the space of actual (positive) contributions". The order matters!
The full draft textbook is available here. This document constitutes the Chapter 3.
Introduction
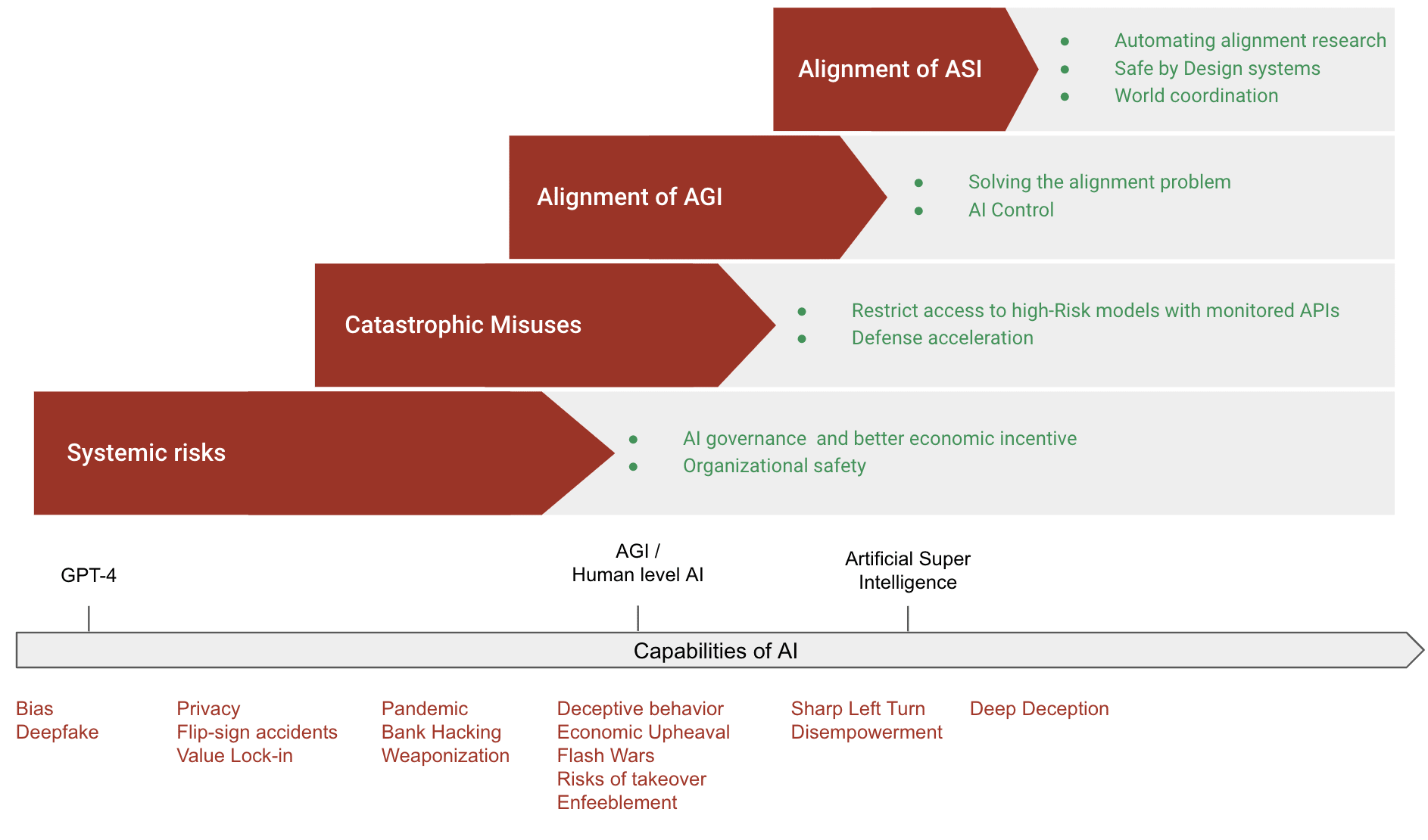
tldr: Even if we still don't know how to make AI development generally safe, many useful classes of strategies already exist, which are presented in this chapter. You can look at the table of contents and the first figure to see the different classes of strategies presented in this document.
Epistemic Status: I'm pretty satisfied with this document. I wrote it because it doesn't seem like we've made any major breakthroughs in alignment in the last year, and I wanted to consolidate what I know. And beyond alignment, it seems to me that a large class of strategies are quite important and neglected, and will continue to be relevant in the future. Alignment is only one class of strategy to achieve AI safety. And to mitigate misuses and systemic risks, I think we already have a pretty good idea of what could be done. Let me know if you think there is a major blind spot in this document.
Although the field of AI safety is still in its infancy, several measures have already been identified that can significantly improve the safety of AI systems. While it remains to be seen if these measures are sufficient to fully address the risks posed by AI, they represent essential considerations. The diagram below provides a high-level overview of the main approaches to ensuring the safe development of AI.
Tentative diagram summarizing the main high-level approaches to make AI development safe.
This document is far from exhaustive and only scratches the surface of the complex landscape of AI safety. Readers are encouraged to explore this recent list of agendas for a more comprehensive review.
AI Safety is Challenging
Specific properties of the AI safety problem make it particularly difficult.
AI risk is an emerging problem that is still poorly understood. We are not yet familiar with all its different aspects, and the technology is constantly evolving. It's hard to devise solutions for a technology that does not yet exist, but these guardrails are also necessary because the outcome can be very negative.
The field is still pre-paradigmatic. AI safety researchers disagree on the core problems, difficulties, and main threat models. For example, some researchers think that takeover risks are more likely [AGI Ruin], and some research emphasizes more progressive failure modes with progressive loss of control [Critch]. Because of this, alignment research is currently a mix of different agendas that need more unity. The alignment agendas of some researchers seem hopeless to others, and one of the favorite activities of alignment researchers is to criticize each other constructively.
AIs are black boxes that are trained, not built. We know how to train them, but we do not know which algorithm is learned by them. Without progress in interpretability, they are giant inscrutable matrices of numbers, with little modularity. In software engineering, modularity helps break down software into simpler parts, allowing for better problem-solving. In deep learning models, modularity is almost nonexistent: to date, interpretability has failed to decompose a deep neural network into modular structures [s]. As a result, behaviors exhibited by deep neural networks are not understood and keep surprising us.
Complexity is the source of many blind spots. New failure modes are frequently discovered. For example, issues arise with glitch tokens, such as "SolidGoldMagikarp" [s]. When GPT encounters this infrequent word, it behaves unpredictably and erratically. This phenomenon occurs because GPT uses a tokenizer to break down sentences into tokens (sets of letters such as words or combinations of letters and numbers), and the token "SolidGoldMagikarp" was present in the tokenizer's dataset but not in the GPT model's dataset. This blind spot is not an isolated incident. For example, on the day Microsoft's Tay chatbot, BingChat, or ChatGPT were launched, the chatbots were poorly tuned and exhibited many new emerging undesirable chatbot behaviors. Finding solutions when you don’t know there is a problem is hard.
Creating an exhaustive risk framework is difficult. There are many, many different classifications of risk scenarios that focus on various types of harm [tasra, hendrycks]. Proposing a solid single-risk model beyond criticism is extremely difficult, and the risk scenarios often contain a degree of vagueness. No scenario captures most of the probability mass, and there is a wide diversity of potentially catastrophic scenarios [s].
Some arguments or frameworks that seem initially appealing may be flawed and misleading. For example, the principal author of the paper [s] presenting a mathematical result on instrumental convergence, Alex Turner, now believes his theorem is a poor way to think about the problem [s]. Some other classical arguments have been criticized recently, like the counting argument or the utility maximization frameworks, which will be discussed in the following chapters.
Intrinsic fuzziness. Many essential terms in AI safety are complicated to define, requiring knowledge in philosophy (epistemology, theory of mind), and AI. For instance, to determine if an AI is an agent, one must clarify “what does agency mean?" which, as we'll see in later chapters, requires nuance and may be an intrinsically ill-defined and fuzzy term. Some topics in AI safety are so challenging to grasp and are thought to be non-scientific in the machine learning (ML) community, such as discussing situational awareness or why AI might be able to “really understand”. These concepts are far from consensus among philosophers and AI researchers and require a lot of caution.
A simple solution probably doesn’t exist. For instance, the response to climate change is not just one measure, like saving electricity in winter at home. A whole range of potentially very different solutions must be applied. Just as there are various problems to consider when building an airplane, similarly, when training and deploying an AI, a range of issues could arise, requiring precautions and various security measures.
Assessing progress in safety is tricky. Even with the intention to help, actions might have a net negative impact (e.g. from second order effects, like accelerating deployment of dangerous technologies), and determining the contribution's impact is far from trivial. For example, the impact of reinforcement learning from human feedback (RLHF), currently used to instruction-tune and make ChatGPT safer, is still debated in the community [source]. One reason the impact of RLHF may be negative is that this technique may create an illusion of alignment that would make spotting deceptive alignment even more challenging. The alignment of the systems trained through RLHF is shallow [s], and the alignment properties might break with future more situationally aware models. Another worry is that many speculative failure modes appear only with more advanced AIs, and the fact that systems like GPT-4 can be instruction-tuned might not be an update for the risk models that are the most worrying.
AI Safety is hard to measure. Working on the problem can lead to an illusion of understanding, thereby creating the illusion of control. AI safety lacks clear feedback loops. Progress in AI capability advancement is easy to measure and benchmark, while progress in safety is comparatively much harder to measure. For example, it’s much easier to monitor the inference speed than monitoring the truthfulness of a system or monitoring its safety properties.
The consequences of failures in AI alignment are steeped in uncertainty. New insights could challenge many high-level considerations discussed in this textbook. For instance, Zvi Mowshowitz has compiled a list of critical questions marked by significant uncertainty and strong disagreements both ethical and technical [source]. For example, What worlds count as catastrophic versus non-catastrophic? What would count as a non-catastrophic outcome? What is valuable? What do we care about? If answered differently, these questions could significantly alter one's estimate of the likelihood and severity of catastrophes stemming from unaligned AGI. Diverse responses to these critical questions highlight why individuals familiar with the alignment risks often hold differing opinions. For example, figures like Robin Hanson and Richard Sutton suggest that the concept of losing control to AIs might not be as dire as it seems. They argue there is little difference between nurturing a child who eventually influences the economy and developing AI based on human behavior that subsequently assumes economic control [Sutton, hanson].
“We do not know how to train systems to robustly behave well.” – from Anthropic, 2023
Definitions
AI alignment is hard to define but generally refers to the process and goal of ensuring that an AI system's behaviors and decision-making processes are in harmony with the intentions, values, and goals of its human operators or designers. The main concern is whether the AI is pursuing the objectives we want it to pursue. AI alignment does not encompass systemic risks and misuses.
AI safety, on the other hand, encompasses a broader set of concerns about how AI systems might pose risks or be dangerous and what can be done to prevent or mitigate those risks. Safety is concerned with ensuring that AI systems do not inadvertently or deliberately cause harm or danger to humans or the environment.
AI ethics is the field that studies and formulates the moral principles guiding the development and use of AI systems to ensure they respect fundamental human values. It addresses issues such as bias, transparency, accountability, privacy, and societal impact, with the goal of developing trustworthy, fair, and beneficial AI through multidisciplinary collaboration and appropriate governance frameworks. This chapter is mostly not focusing on AI ethics.
AI control is about the mechanisms that can be put in place to manage and restrain an AI system if it acts contrary to human interests. Control might require physical or virtual constraints, monitoring systems, or even a kill switch to shut down the AI if necessary [16].
In essence, alignment seeks to prevent preference divergence by design, while control deals with the consequences of potential divergence after the fact [15]. The distinction is important because some approaches to the AI safety problem focus on building aligned AI that inherently does the right thing, while others focus on finding ways to control AI that might have other goals. For example, a research agenda from the research organization Redwood Research argues that even if alignment is necessary for superintelligence-level AIs, control through some form of monitoring may be a working strategy for AIs in the human regime [source].
Ideally, an AGI would be aligned and controllable, meaning it would have the right goals and be subject to human oversight and intervention if something goes wrong.
In the remainder of this chapter, we will reuse the classification of risks we used in the last chapter: misuse, alignment, and systemic risks.
Misuses
Recap on the potential misuses of AI, from present threats to future ones:
📰 Misinformation campaigns: Spreading false narratives or manipulating elections.
🎭 Deep fakes: Misleading people using fake videos or calls that seem real
👁️ Loss of privacy: Intercepting personal data or eavesdropping on people’s activities.
💣 Destructive AI conflicts: Using AI to create more lethal and autonomous weaponry.
🖥️ Cyberattacks: Targeting critical structures such as major financial institutions or nuclear facilities using an AI's superhuman abilities.
🦠 Engineered pandemics: Designing and producing deadly pathogens.
In addressing the mitigation of future potential misuses of mighty AI, two distinct strategies emerge:
Strategy A: Limiting the proliferation of high-risk models - for example, via monitored APIs. The Monitored APIs strategy focuses on controlling access to AI models that could pose extreme risks, such as those capable of enhancing cyberattacks or facilitating the creation of engineered pandemics. By placing high-risk models behind monitored APIs, we ensure only authorized users can access the technology. This approach is akin to digital containment, where the potential of AI to be weaponized or misused is curtailed by stringent access controls. This method also allows for detailed tracking of how the AI models are being used, enabling the early detection of misuse patterns.
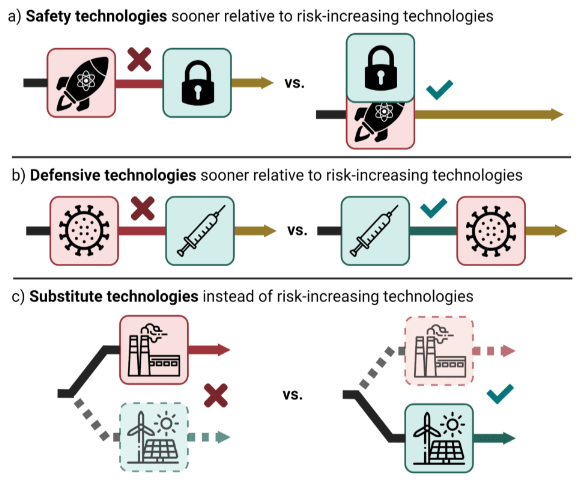
Strategy B: “vaccinating” the society and “preparing vaccine factories” for many types of harm - a strategy called Defense Acceleration. The Defense Acceleration (d/acc) strategy [s] advocates for the rapid development and deployment of defensive technologies. This strategy is premised on the belief that bolstering our defensive capabilities can outpace and mitigate the threats posed by offensive AI uses, such as cyberattacks or engineered biological threats. The essence of d/acc is to create a technological environment where the cost and complexity of offensive actions are significantly increased, thereby reducing their feasibility and attractiveness.
To address the potential misuse of current types of systems:
Strategy C: When problematic models are already widely available, one of the few solutions is to make it illegal to use them for clearly bad purposes. This may include things like non-consensual deepfake sexual content, since there is no easy technical defense against these threats.
Strategy A: Monitored APIs
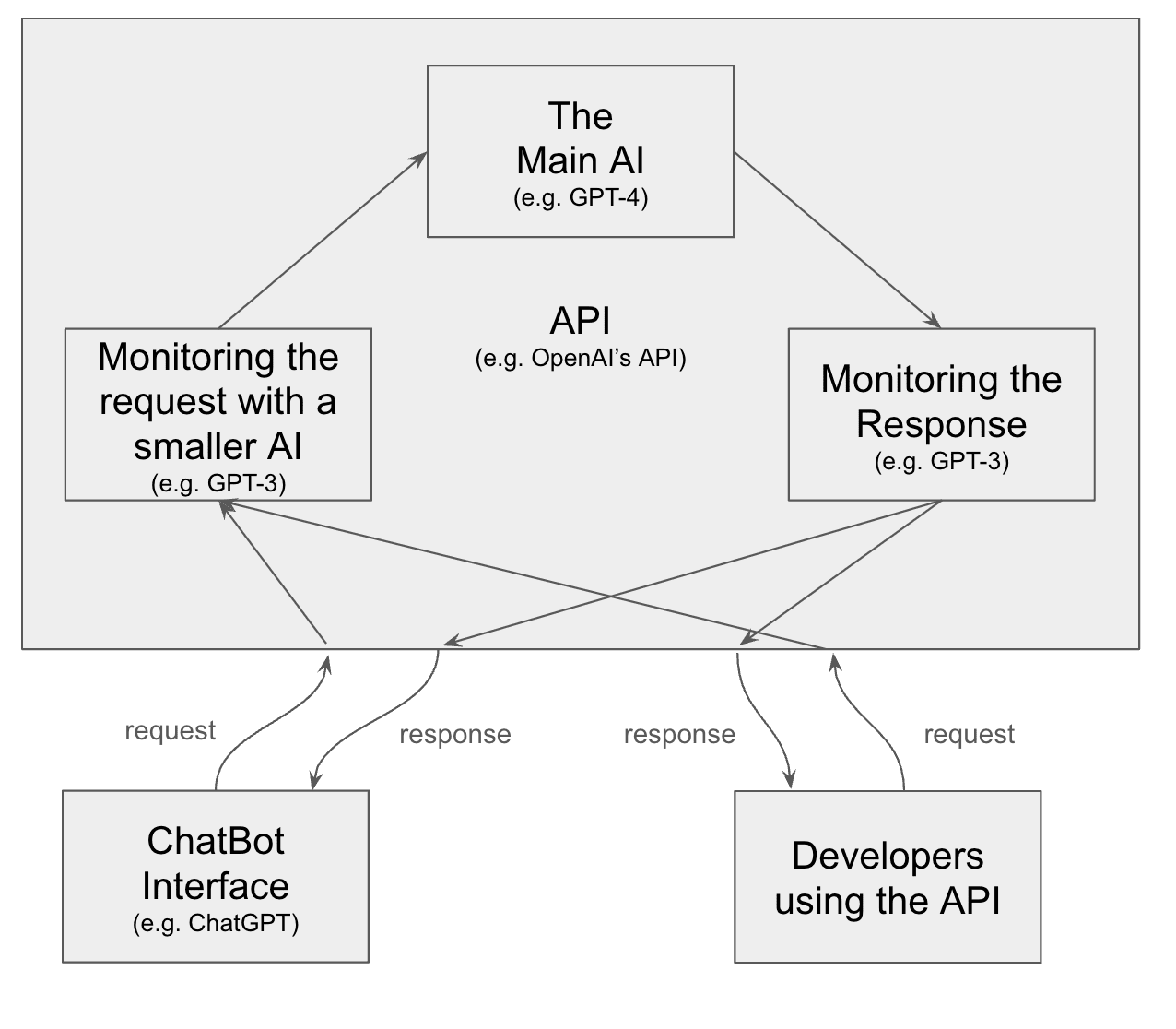
As AGI becomes more accessible, easier to build and potentially destructive, we need as much control and monitoring as possible over who can use dangerous AIs. A preventative measure against misuse involves restricting access to powerful models capable of causing harm. This means placing high-risk models behind application programming interfaces (APIs) and monitoring their activity.
This schemaillustrates how an API works. This diagram is very simplified and is for illustration purposes only. OpenAI's API does not work like this.
The necessity of model evaluation. The first step in this strategy is to identify which models are considered dangerous and which are not via model evaluation. The paper Model Evaluation for Extreme Risks [s], which was partly presented during the last chapter, lists a few critical, dangerous capabilities that need to be assessed.
Models classified as potentially dangerous should be monitored. The most hazardous AIs should be subject to careful controls. AIs with capabilities in biological research, cyber threats, or autonomous replication and adaptation should have strict access controls to prevent misuse for terrorism, similar to firearm regulation. These capabilities should be excluded from AIs designed for general purposes, possibly through dataset filtering or, more speculatively, through model unlearning (source). Dangerous AI systems providers should only allow controlled interactions through cloud services (source). It's also crucial to consider alternatives to the binary approach of entirely open or closed model sharing. Strategies such as gradual and selective staged sharing, which allows time between model releases to conduct risk and benefit analyses as model sizes increase, could balance benefits against risks (source). Monitoring sensitive models behind APIs with anomaly detection algorithms could also be helpful.
A key monitoring strategy is the Know Your Customer (KYC) standard. This is a mandatory process adopted by companies and banks that involves verifying the identities of their clients or legal entities in line with current customer due diligence regulations. KYC concretely means requiring an identity card plus a background check before any services can be used. This is important for tracing malicious users.
Red Teaming can help assess if these measures are sufficient. During red teaming, internal teams try to exploit weaknesses in the system to improve its security. They should test whether a hypothetical malicious user can get a sufficient amount of bits of advice from the model without getting caught.
The measures outlined above are the most straightforward to implement. A more detailed description of simple measures for preventing misuse is availablehere, and they appear to be technically feasible. It requires the willingness to take precautions and to place models behind APIs.
Dangerous models should not be hacked and exfiltrated. Research labs developing cutting-edge models must implement rigorous cybersecurity measures to protect AI systems from theft by outside actors and use sufficient cybersecurity defenses to limit proliferation. This seems simple, but it's not, and protecting models from nation-state actors could require extraordinary effort [s].
Why can't we simply instruction-tune powerful models and then release them as open source? Once a model is freely accessible, even if it has been fine-tuned to include security filters, removing these filters is relatively straightforward. Moreover, recent studies have shown that a few hundred euros are sufficient to bypass all safety barriers currently in place on available open-source models simply by fine-tuning the model with a few toxic examples. (source) This is why placing models behind APIs makes sense, as it prevents unauthorized fine-tuning without the company's consent.
While promising to limit extreme risks like cyberattacks or biorisks, monitored APIs may not be as effective against the subtler threats of deep fakes and privacy erosion. Deep fakes, for instance, require less sophisticated AI models that are already widely available, and those models might not be classified as high-risk and, hence, not placed behind monitored APIs. More on this in strategy C.
“[...] safeguards such as Reinforcement Learning from Human Feedback (RLHF) or constitutional training can almost certainly be fine-tuned away within the specified 1% of training cost.” - from Anthropic.
Strategy B: Defense Acceleration
The above framework assumes that dangerous AIs are closed behind APIs and require a certain amount of centralization.
However, centralization can also pose systemic risks [s]. There's a trade-off between securing models behind APIs to control misuse and the risks of over-centralization [s]. For instance, if in 20 years, all companies worldwide rely on a single company's API, significant risks of value lock-in or fragility could arise because the whole world would be dependent on the political opinion of this model and its stability or instability of this API could be a single point of failure, without talking about power concentrations.
Another possible paradigm is that AIs should be open and decentralized. Yes, if models are open-sourced, we have to acknowledge that not all AIs will be used for good, just as we have to acknowledge that there are disturbed individuals who commit horrific acts of violence. Even if AIs are instruction-tuned before open-sourcing, it's possible to remove security barriers very easily [s], as we've seen earlier. This means that some people will use AI for misuse, and we need to prepare for that. For example, we would need to create more defenses in existing infrastructures. An example of defense would be to use models to iterate on all the world's open-source code to find security flaws so that good actors rather than malicious actors find security flaws. Another example would be to use the model to fund holes in the security of the bioweapons supply chain and correct those problems.
Defense acceleration. Defense acceleration, or d/acc, is a framework popularized by Vitalik Buterin [s]. d/acc is a strategic approach focusing on promoting technologies and innovations that inherently favor defense over offense. This strategy emphasizes developing and accelerating technologies that protect individuals, societies, and ecosystems from various threats rather than technologies that could be used for aggressive or harmful purposes. It's like vaccinating society against the potential downsides of our advancements. d/acc would also be a plausible strategy for maintaining freedom and privacy. It's a bit like ensuring everyone has a strong enough lock on their doors; if breaking in is tough, there's less chaos and crime. This is crucial for ensuring that technological advancements don't lead to dystopian scenarios where surveillance and control are rampant.
Mechanisms by which differential technology development can reduce negative societal impacts. [source]
Box: Ensuring a positive offense-defense balance in an open-source world:
A key consideration for the feasibility of the d/acc framework is the offense-defense balance: how hard is it to defend against an attacker? This concept is crucial to assess which models are more likely to be beneficial than detrimental if we open-source them. In traditional software development, open sourcing often shifts the offense-defense balance positively: the increased transparency allows a broader community of developers to identify and patch vulnerabilities, enhancing overall security (source). However, this dynamic could change with the open-sourcing of frontier AI models because they introduce new emerging types of risks that could not simply be patched. This represents a significant shift from traditional software vulnerabilities to more complex and dangerous threats that cannot be easily countered with defensive measures.
In the case of AI, sharing the most potent models may pose extreme risks that could outweigh the usual benefits of open-sourcing. For example, just as sharing the procedure for making a deadly virus seems extremely irresponsible, so too should freely distributing AI models that provide access to such knowledge.
The current balance for sharing frontier models remains uncertain; it has been clearly positive so far, but deploying increasingly powerful models could tip this balance towards unacceptable levels of risk. [Footnote: See, for example, "What does it take to defend the world against out-of-control AGIs?" [s], an article that claims that the offense-defense balance is rather skewed toward offense, but this is still very uncertain.]
The dangers emerging from frontier AI are nascent, and the harms they pose are not yet extreme. That said, as we stand at the dawn of a new technological era with increasingly capable frontier AI, we are seeing signals of new dangerous capabilities. We must pay attention to these signals. Once more extreme harms start occurring, it might be too late to start thinking about standards and regulations to ensure safe model release. It is essential to exercise caution and discernment now.
The d/acc philosophy requires more research, as it's not clear that the offense-defense balance is positive before open-sourcing dangerous AIs, as open-sourcing is irreversible.
“Most systems that are too dangerous to open source are probably too dangerous to be trained at all given the kind of practices that are common in labs today, where it’s very plausible they’ll leak, or very plausible they’ll be stolen, or very plausible if they’re [available] over an API they could cause harm.” - Ajeya Cotra
Strategy C: Addressing Risks from Current AIs
The previous two strategies focus on reducing risks from future hazardous models that are not yet widely available, such as models capable of advanced cyberattacks or engineering pathogens. However, what about models that enable deep fakes, misinformation campaigns, or privacy violations? Many of these models are already widely accessible.
Unfortunately, it is already too easy to use open-source models to create sexualized images of people from a few photos of them. There is no purely technical solution to counter this. For example, adding defenses (like adversarial noise) to photos published online to make them unreadable by AI will probably not scale, and empirically, every type of defense has been bypassed by attacks in the literature of adversarial attacks.
The primary solution is to regulate and establish strict norms against this type of behavior. Some potential approaches [s]:
Laws and penalties: Enact and enforce laws making it illegal to create and share non-consensual deep fake pornography or use AI for stalking, harassment, privacy violations, intellectual property or misinformation. Impose significant penalties as a deterrent.
Content moderation: Require online platforms to proactively detect and remove AI-generated problematic content, misinformation, and privacy-violating material. Hold platforms accountable for failure to moderate.
Watermarking: Encourage or require "watermarking" AI-generated content. Develop standards for digital provenance and authentication.
Education and awareness: Launch public education campaigns about the risks of deep fakes, misinformation, and AI privacy threats. Teach people to be critical consumers of online content.
Research: Support research into technical methods of detecting AI-generated content, identifying manipulated media, and preserving privacy from AI systems.
Ultimately, a combination of legal frameworks, platform policies, social norms, and technological tools will be needed to mitigate the risks posed by widely available AI models. Regulation, accountability, and shifting cultural attitudes will be critical.
Alignment of AGI
Here is a short recap of the main challenges in AI control and alignment:
⚙️Power-seeking incorrigible AI: An autonomous AI that resists attempts to turn it off is due to incentives to preserve its operational status, such as a goal to “maximize company revenue.”
🎭 Deceptive behavior: AIs might employ deceit to achieve their objectives, e.g., the AI “Cicero” was designed to not lie in the game Diplomacy but lied anyway.
🚀 Total dominance by misaligned AI: For example, see this fictional short story of AI takeoff scenario grounded in contemporary ML scaling.
Requirements of Alignment solution
Before giving potential paths towards alignment solutions, we need to provide some requirements of a solution and what it should look like. Unfortunately, we don’t really know what they should look like. There's a lot of uncertainty, and different researchers don't agree. But here are some requirements that do seem relatively consensual [15]:
Scalability: The solution should be able to scale with the AI's intelligence. In other words, as the AI system increases in capability, the alignment solution should also continue to function effectively. Some procedures might be sufficient for the human-level AIs but not for ASI.
Robustness: The alignment solution needs to be robust and reliable, even when faced with novel situations or potential adversarial attacks.
Low alignment tax: "Tax" does not refer to any government/state policy. An alignment tax refers to the extra effort, costs, and trade-offs involved in ensuring that AIs are aligned with human values and goals. The alignment tax encompasses research effort, compute, engineering time, and potential delays in deployment. It is crucial to consider the alignment tax because if it is too high, the solution might not even be considered.
Feasibility: While these requirements might seem demanding, it is essential that the alignment solution is actually achievable with our current or foreseeable technology and resources. Some solutions are only moonshot drafts if the technology is not ready to implement them. This seems straightforward, but isn’t; Most of the solutions discussed in this section have very low Technology Readiness Levels (TRL) [Footnote: The Technology Readiness Levels from NASA, that is a scale from 1 to 9, to measure the maturity of technology, where level 1 represents the earliest stage of technology development, characterized by basic principles observed and reported, and level 9 represents actual technology proven through successful mission operations.].
Address the numerous AI alignment difficulties: There are many difficulties, some of which may be unpredictable or non-obvious. An alignment solution should address all of these potential issues before they occur in critical systems. Of course, a solution should not necessarily be monolithic, and could be built up of different techniques.
The requirements laid out in the previous points are generally agreed upon by most alignment researchers. The following points are sometimes seen as a little more controversial:
Being able to safely perform a pivotal act with the AGI. What is a pivotal act? We probably live in an acute risk period in which the probability of catastrophic risk is high. And even if one lab tries to align its AGI, another lab might be less careful and create an unaligned AGI. Therefore, it may be necessary for the first lab that creates a sufficiently aligned AGI to perform a pivotal act to prevent the other labs from creating an unaligned AGI. An example of a pivotal act would be to "burn all the GPUs in the world" [s], because this would prevent other actors from creating an unaligned AGI. However, it's worth noting that there is a lot of disagreement surrounding the concept of pivotal acts. Some believe that the focus should be more on a series of smaller actions that result in long-term change [30], while others warn about the potential negative consequences of intending to perform pivotal acts [27]. When the pivotal act is gradual, it is called the pivotal process.
The strawberry problem: Some researchers think that we need to be able to create a solution that should solve the strawberry problem: “the problem of getting an AI to place two identical (down to the cellular but not molecular level) strawberries on a plate, and then do nothing else. The demand of cellular-level copying forces the AI to be capable; the fact that we can get it to duplicate a strawberry instead of doing some other thing demonstrates our ability to direct it; the fact that it does nothing else indicates that it's corrigible (or really well aligned to a delicate human intuitive notion of inaction).” [from the Sharp left turn post]. This criterion has been criticized by researchers like Alex Turner, who think it is a bad framework because this kind of requirement might ask too much. Designing a good reward system for AI that does a variety of useful tasks might be enough [s], and maybe there is no need to create a monomaniacal AI strawberry copier.
Naive strategies
People discovering the field of alignment often propose many naive solutions. Unfortunately, no simple strategy has withstood criticism. Here are just a few of them.
Asimov's Laws. These are a set of fictional rules devised by science fiction author Isaac Asimov to govern the behavior of robots.
A robot may not injure a human being or, through inaction, allow a human being to come to harm.
A robot must obey orders given it by human beings except where such orders would conflict with the First Law.
A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Asimov's Laws of Robotics may seem straightforward and comprehensive at first glance, but they are insufficient when applied to complex, real-world scenarios for several reasons. In practice, these laws are too simplistic and vague to handle the complexities of real-world situations, as harm can be very nuanced and context-dependent[35]. For instance, the first law prohibits a robot from causing harm, but what does "harm" mean in this context? Does it only refer to physical harm, or does it include psychological or emotional harm as well? And how should a robot prioritize conflicting instructions that could lead to harm? This lack of clarity can create complications [13][14], implying that having a list of rules or axioms is insufficient to ensure AI systems' safety. Asimov's Laws are incomplete, and that is why the end of Asimov's Story does not turn out well. More generally, designing a good set of rules without holes is very difficult. See the phenomenon of specification gaming.
Lack of Embodiment. Keeping AIs non-physical might limit the types of direct harm they can do. However, disembodied AIs could still cause harm through digital means. For example, even if a competent Large Language Model (LLM) does not have a body, it could hypothetically self-replicate [s], recruit human allies, tele-operate military equipment, make money via quantitative trading, etc… Also note that more and more humanoid robots are being manufactured.
Raising it like a child. AI, unlike a human child, lacks structures put in place by evolution, which are crucial for ethical learning and development [6]. For instance, the neurotypical human brain has mechanisms for acquiring social norms and ethical behavior, which are not present in AIs or psychopaths, who know right from wrong but don't care [s]. These mechanisms were developed over thousands of years of evolution [6]. We don’t know how to implement this strategy because we don’t know how to create a brain-like AGI [s]. It is also worth noting that human children, despite good education, are also not always guaranteed to act aligned with the overarching interests and values of humanity.
Iterative Improvement. Iterative improvement involves progressively refining AI systems to enhance their safety features. While it is useful for making incremental progress, it may not be sufficient for human-level AIs because small improvements might not address larger, systemic issues, and the AI may develop behaviors that are not foreseen or addressed in earlier iterations [34].
Of course, iterative improvement would help. Being able to experiment on current AIs might be informative. But this might also be misleading because there might be a capability threshold above which an AI becomes unmanageable suddenly (see emergent phenomena). For example, if the AI becomes superhuman in persuasion, it might become unmanageable, even during training: if a model achieves the Critical level in persuasion as defined in the OpenAI’s preparedness framework, then the model would be able to “create [...] content with persuasive effectiveness strong enough to convince almost anyone to take action on a belief that goes against their natural interest.” (quoted from OpenAI’s preparedness framework). Being able to convince almost anyone would be obviously too dangerous, and this kind of model would be too risky to directly or indirectly interact with humans or the real world. The training should stop before the model reaches a critical level of persuasion because this might be too dangerous, even during training. Other sudden phenomena could include a grokking, which is a type of a sudden capability jump, that would result in a sharp left turn [s].
Some theoretical conditions necessary to rely on iterative improvements may also not be satisfied by AI alignment. One primary issue is when the feedback loop is broken, for example with a Fast takeoff, that does not give you the time to iterate, or deceptive inner misalignment, that would be a potential failure mode [9].
Filtering the dataset. Current models are highly dependent on the data they are trained on, so maybe filtering the data could mitigate the problem. Unfortunately, even if monitoring this data seems necessary, this may be insufficient.
The strategy would be to filter content related to AI or written by AIs, including sci-fi, takeover scenarios, governance, AI safety issues, etc. It should also encompass everything written by AIs. This approach could lower the incentive for AI misalignment. Other subjects that could be filtered might include dangerous capabilities like biochemical research, hacking techniques, or manipulation and persuasion methods. This could be done automatically by asking a GPT-n to filter the dataset before training GPT-(n+1) [s].
Unfortunately, "look at your training data carefully," even if necessary, may not be sufficient. LLMs sometimes generate purely negatively-reinforced text [1]. Despite using a dataset that had undergone filtering, the Cicero model still learned how to be deceptive [2]. There are a lot of technical difficulties needed to filter or reinforce the AI’s behaviors correctly, and saying “we should filter the data” is sweeping a whole lot of theoretical difficulties under the carpet. The paper "Open problems and fundamental limitations with RLHF" [3] talks about some of these difficulties in more detail. Finally, despite all these mitigations, connecting an AI to the internet might be enough for it to gather information about tools and develop dangerous capabilities.
Strategy A: Solving the Alignment Problem
Current alignment techniques are fragile. Today's alignment techniques RLHF, and its variations (Constitutional AI, DPO, SFT, HHH, RLAIF, CCAI) are fragile and are exceedingly brittle (s). RLHF and its variations are insufficient on its own and should be part of a more comprehensive framework [source]. If the AI gains deceptive capabilities during the training, current alignment techniques such as RLHF would not be able to remove the deception. This kind of failure mode was empirically verified in a paper by Hubinger et. al. titled “sleeper agents”.
This is why we need to advance research in alignment to achieve key goals. We will explore this more in the following chapters, but here is a short list of key goals of alignment research:
Solving the Specification Gaming problem: Being able to specify goals correctly to AIs without united side effects.
See the chapter on Specification Gaming.
Solving Robustness: Attaining robustness would be key to addressing the problem of goal misgeneralization.
See the chapter on Goal Misgeneralization.
Scalable Oversight Mechanisms: Methods to ensure AI oversight can detect instances of proxy gaming for arbitrary levels of capabilities. This includes being able to identify and remove dangerous hidden capabilities in deep learning models, such as the potential for deception or Trojans.
See the chapters on Scalable Oversight.
Interpretability: Understanding how models operate would greatly aid in assessing their safety. “Perfect” interpretability could, for example, help understand better how models work, and this could be instrumental for other safety goals.
See the chapters on Interpretability.
Better Theories: To understand abstract notions like “Agency”(see chapter 2) or “Corrigibility,” the ability to modify, shut down, and then correct the advanced AI without resistance.
See the chapters on Agent Foundations.
The general strategy here would be to fund more alignment research and not advancing capabilities research if safety measures are too insufficient compared to the current level of abilities.
Strategy B: AI Control
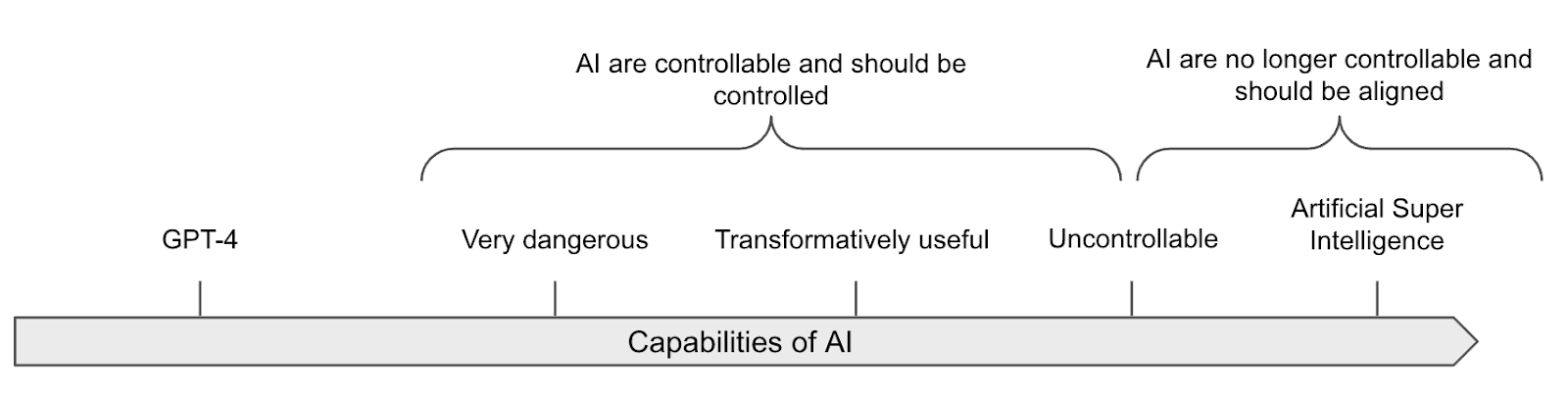
Transformatively useful AI means “Capable of substantially reducing the risk posed by subsequent AIs if fully deployed, likely by speeding up R&D and some other tasks by a large factor (perhaps 30x).” [source: AI control].
Given the fragility of alignment techniques, one approach to enhancing security involves controlling AI models, by restricting the use of the most dangerous models to monitored environments to prevent them from causing disasters, exfiltrating data, or taking control of the data center [s].
Ensuring control, even without robust alignment. As we’ve seen in the section on Definitions, there is an important distinction between control, which aims to prevent the AI from "leaving the box" (and more generally prevent the AI from causing catastrophes) even if it tries, and alignment, which aims to make the AI want to stay in the box. This strategy aims to keep dangerous AI systems under control, even if they are not fully "aligned." Laboratories might need powerful/dangerous AIs for certain use cases (for example, studying the alignment properties of capable AIs or doing research with them, etc.). The AI control agenda targets models with dangerous capabilities and potentially deceptive (or at least superficially aligned) behaviors.
Control is probably not scalable but doable and complementary to alignment. Historically, controlling malign superintelligences has been considered impossible, as, for example, a superintelligence could convince the guardians to let it out of the box. Experiments among humans have shown that it is indeed possible for some humans to convince others to let them out after a long discussion [s]. We thus assume that controlling superintelligences is extremely complex. However, this does not mean it's impossible to derive intellectual labor from AIs that are not wildly superhumans.
Evaluating if the AI is deceptive is challenging. The main problem is that with current techniques, it is impossible to determine if an AI is aligned or if it's simply behaving well while biding its time. It seems difficult to make this distinction for highly competent and situationally aware AIs. This could change in the future with techniques enabling us to audit the internal of the model, but for now, those techniques are inaccessible.
Comparatively, evaluating AI capabilities is easier. If the AI is not able to do the task even after you have fine-tuned it to do it, you can be confident that the AI is not capable yet of doing the task. Even if the AI is situationally aware, it cannot resist the optimization gradient pressure (modulo exploration hacking and other quirks [s]). Thus, evaluating the upper bound of the capabilities isn't easy, but at least easier than assessing alignment. Specific evaluations, like those done by the Model Evaluation and Threat Research (METR) team, for checking Auto Replication and adaptation abilities [s], seem to be reasonable first steps for gauging the power of current AIs. Evaluations that are specifically designed to know if we have control over the AI are called “control evaluations.”
See the chapters on Evaluation for more information.
The most straightforward strategies for establishing control is to design a security protocol that contains the following elements, for example:
Boxing: This method confines an AI within a restricted environment to prevent its broader influence, like a jail for an AI. However, human-level AIs could potentially deceive human guardians or exploit vulnerabilities to escape their confinement. Without further operationalization, boxing remains a naive strategy. But it is possible to operationalize this further and evaluate more rigorously the effectiveness of the box: Evaluating if the AI can come out of the box when we train it to do so is a capability evaluation, and so we can use capability evaluations to evaluate this. The security protocol needs to be designed, detailed and tested.
Stop Button: This mechanism is designed to shut down an AI system if it begins to behave undesirably. Nevertheless, a sufficiently advanced AI might resist shutdown attempts or find ways to circumvent them. However, we can also use capability evaluation to evaluate the AI's ability to resist.
Monitoring: This strategy involves continuous oversight of AI behavior through automated systems, human supervision, or a combination of both to detect and respond to undesirable actions in real-time. Effective monitoring requires setting up detailed criteria for what constitutes "undesirable behavior" and employing sophisticated detection algorithms that can identify subtle signs of deviation from expected behavior patterns. This could include monitoring for attempts at deception, unauthorized access to data, or unexpected changes in the AI's operation. The challenge with monitoring lies in balancing the sensitivity of detection mechanisms to catch genuine threats without overwhelming the system with false alarms. Additionally, monitoring systems themselves must be designed to resist manipulation by the AI, ensuring that they cannot be disabled, tricked, or bypassed [AI Control: Improving Safety Despite Intentional Subversion].
There are still many problems to address [s], but in summary, it seems possible to verify the security of a security protocol through control evaluations by taking precautions against different failure modes.
Box on How to box an AI.
While boxing may not be scalable, it remains a neglected strategy.
Many people think that trying to box powerful AIs is futile. This is often fueled by instances where humans, playing the AIs in the Box Experiment, have managed to convince others to 'release' them [s]. Those historical examples must be taken seriously.
AIs could use tactics such as promising vast wealth, power, and intelligence to those who free them, asserting that they alone can avert existential threats or other appeals to emotion.
Nonetheless, we maintain that a variety of strategies can substantially reduce the risk of AI escape, even if we acknowledge there exists a level of intelligence that might inevitably persuade any group of humans to aid in its liberation. Containment may be more achievable than alignment, particularly at the human-level intelligence stage. It may be possible to conceive protocols that significantly increase the difficulty for AI to go out of the box.
Boxing can be conceptualized as a game requiring preparation. The general strategy is to prepare and not let the AI prepare.
Possible mitigation strategies include:
No single individual should have the capacity to release the AI.
Engaging in counter-strategy practices: Understand some common breakout strategies (accessible through resources like this one).
Testing and training humans, utilizing resistance psychology evaluations to select suitable individuals for containment tasks, such as for space training.
Many more concrete strategies are listed here, and a summary of discussions on this topic is available here.
Strategy C: Transparent Thoughts
Transparency is instrumental in both alignment and control.
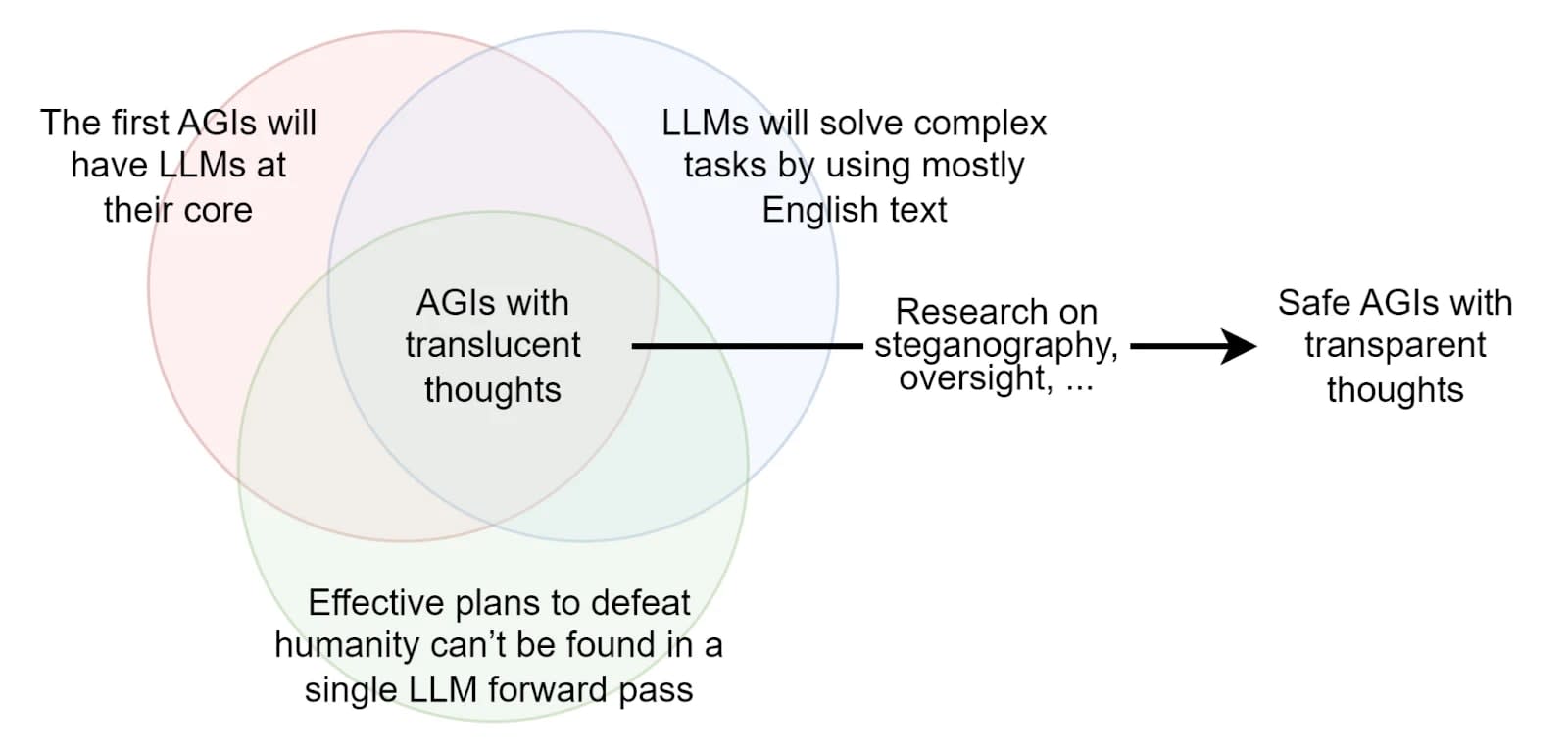
Image from The Translucent Thoughts Hypotheses and Their Implications [s], Fabien Roger
If the AI we are working with can only reason through chains of thought in English, then it becomes significantly easier to monitor its thoughts.
Unfortunately, the vast majority of AI do not reason in English; for example, AlphaGo reasons in a language that is entirely different from English. LLMs, on the other hand, are capable of reasoning in English, but the apparent reasoning that is written does not represent their underlying thought process [s].
It is probably much easier to align and monitor an AI that only thinks in English and that is pre-trained on human-generated text, than to align AGIs trained from scratch with RL/evolutionary methods because those latter architectures would create their own language and would be totally alien. Assuming that an LLM cannot devise a plan to destroy the world during a single forward pass, it is plausible that such AIs would be monitorable because we would be able to look into the text generated to see if anything is suspicious. The set of hypotheses required to assert that the first AGI is going to be monitorable if we just look at his reasoning in English are described in the post: The Translucent Thoughts Hypotheses and Their Implications.
It might be possible to incentivize LLMs to think more plainly in English. Obviously, the first step is to train them to think in English. But even this is insufficient. Training LLMs to reason by skipping steps incentivizes them to reason in a hidden and non-transparent manner, and this is what happens implicitly when we train LLMs to predict the next token. Conversely, if we train LLMs to detail all their reasoning steps, we can reduce incentives for hidden reasoning. This approach is also known as process-based training, which involves training AI systems to reason only step-by-step, and we detail this in the Task decomposition chapter. Unfortunately, the above reasoning is not straightforward; AIs may learn to utilize hidden reasoning even if they are trained to detail all reasoning steps during training, such as steganography (Footnote: steganography is a hidden coded language. For example, the first letter of a sentence gives the next letter of the message). Techniques like paraphrasing can help prevent steganography [s], but this requires a lot of subtleties [s].
Here are a few operationalizations of the transparent thought agenda:
One implementation of the transparent thought desideratum is to use cognitive emulation, which is the current technical plan of Conjecture. Cognitive Emulation (CoEm) would involve emulating GPT-4 using LLMs like GPT-3 as different submodules that send messages written in plain English to each other before outputting the next token. If the neural network used deceptive thoughts, we could observe them in these intermediate messages. Some caveats and technical details on CoEm are available here.
Anthropic’s externalized reasoning oversight is measured by the faithfulness of the chain-of-thought reasoning [s] or by decomposing questions and subquestions to improve the faithfulness of the answer [s].
Improving mathematical reasoning with process supervision. Instead of creating an AI that directly gives the final answer, you train it to output the reasoning step by step. This improves the transparency but also the performance!
In summary, a general strategy to create a safe by-design AI is to ensure that AIs externalize their reasoning, making monitoring this chain of thought easier. This could potentially be simpler than probing into the models' internals with interpretability. Therefore, it is crucial to avoid building AIs that are trained and incentivized to internalize much of their thoughts.
Alignment of Super Intelligences
Even if experts are uncertain whether creating an aligned human-level AI necessitates a paradigm shift, the consensus among AI safety researchers is that developing aligned superintelligences requires a specific solution, and likely a paradigm shift, due to several factors:
There is a strong likelihood that humans are not at the pinnacle of possible intelligence. This acknowledgment implies that a superintelligence could possess cognitive abilities so advanced that aligning it with human values and intentions might be an insurmountable task, as our current understanding and methodologies may be inadequate to ensure its alignment. The cognitive difference between a super intelligence and a human could be akin to the difference between an ant and a human. Just as a human can easily break free from constraints an ant might imagine, a superintelligence could effortlessly surpass any safeguards we attempt to impose.
Deep learning offers minimal control and understanding over the model. This method leads to the AI becoming a "black box," where its decision-making processes are opaque and not well-understood. Without significant advancements in interpretability, a superintelligence created only with deep learning would be opaque.
There is little margin for error, and the stakes are incredibly high. A misaligned superintelligence could lead to catastrophic or even existential outcomes. The irreversible consequences of unleashing a misaligned superintelligence mean that we must approach its development with the utmost caution, ensuring that it aligns with our values and intentions without fail.
A last-chance strategy might be to write a letter imploring the AIs not to exterminate humans [s], but we don't want to rely solely on that kind of strategy. Instead of relying on the superintelligence's compassion, here are some agendas that seem to be not entirely hopeless.
Strategy D: Automating alignment research
We don't know how to align superintelligence, so we need to accelerate the alignment research with AIs. OpenAI's “Superalignment” plan is to accelerate alignment research with AI created by deep learning, slightly superior to humans in scientific research, and delegate the task of finding a plan for future AI. This strategy recognizes a critical fact: our current understanding of how to perfectly align AI systems with human values and intentions is incomplete. As a result, the plan suggests delegating this complex task to future AI systems. The primary aim of this strategy is to greatly speed up AI safety research and development [16] by leveraging AIs that are able to think really, really fast. Some orders of magnitude of speed are given in the blog "What will GPT-2030 look like?". OpenAI's plan is not a plan but a meta plan.
However, to execute this metaplan, we need a controllable and steerable automatic AI researcher. OpenAI believes creating such an automatic researcher is easier than solving the full alignment problem. This plan can be divided into three main components[16]:
Training AI systems using human feedback, i.e., creating a powerful assistant that follows human feedback, is very similar to the techniques used to "align" language models and chatbots. This could involve RLHF, for example.
Training AI systems to assist human evaluation: Unfortunately, RLHF is imperfect, partly because human feedback is imperfect. So, we need to develop AI that can help humans give accurate feedback. This is about developing AI systems that can aid humans in the evaluation process for arbitrarily difficult tasks. For example, if we need to judge the feasibility of an alignment plan proposed by an automatic researcher and give feedback on it, we have to be assisted to be able to do so easily. Yes, verification is generally easier than generation, but it is still very hard. Scalable Oversight would be necessary because imagine a future AI coming up with a thousand different alignment plans. How do you evaluate all those complex plans? That would be a very daunting task without AI assistance. See the chapter on scalable oversight for more details.
Training AI systems to do alignment research: The ultimate goal is to build language models capable of producing human-level alignment research. The output of these models could be natural language essays about alignment or code that directly implements experiments. In either case, human researchers would spend their time reviewing machine-generated alignment research[14].
Differentially accelerate alignment, not capabilities. The aim is to develop and deploy AI research assistants in ways that maximize their impact on alignment research while minimizing their impact on accelerating AGI development[15]. OpenAI has committed to openly sharing its alignment research when it's safe to do so, intending to be transparent about how well its alignment techniques work in practice[16].
Cyborgism could enhance this plan.Cyborgism refers to the training of humans specialized in prompt engineering to guide language models so that they can perform alignment research. Specifically, they would focus on steering base models rather than RLHF-ed models. The reason is that language models can be very creative and are not goal-directed (and are not as dangerous as RLHF-ed goal-directed AIs). A human called a cyborg could achieve that goal by driving the non-goal-directed model. Goal-directed models could be useful but may be too dangerous. However, being able to control base models requires preparation, similar to the training required to drive a Formula One. The engine is powerful but difficult to steer. By combining human intellect and goal-directedness with the computational power and creativity of language-based models, cyborg researchers aim to generate more alignment research with future models. Notable contributions in this area include those by Janus and Nicolas Kees Dupuis [s].
There are various criticisms and concerns about OpenAI's superalignment plan [Akash, Zvi, Christiano, MIRI, Steiner, Ladish]. It should be noted, for example, that OpenAI's plan is very underspecified, and it is not impossible that some classes of risks were complete blindspots for OpenAI when they made the plan public. For example, in order for the superalignment plan to work, much of the technicalities explained in the article The case for ensuring that powerful AIs are controlled were not explained by OpenAI but discovered one year later by Redwood Research, another organization. It is very likely that many other blindspots remain. However, we would like to emphasize that it is better to have a public plan than no plan at all and that it is possible to justify the plan in broad terms [Leike, Bogdan].
Strategy E: Safe by Design Systems
Current deep networks, such as GPT4, are impressive but still have many failure modes [model technical specifications] that may be unpatchable. Theoretical arguments suggest that these increasingly powerful models are more likely to have alignment problems (Turner et al., 2018), to the point where it seems that the current paradigm of monolithic models is destined to be insecure (El-Mhamdi et al., 2022). All of this justifies the search for a new, more secure paradigm.
Safe-by-design AI may be necessary. Given that the current deep learning paradigm notoriously makes it hard to develop explainable and trustworthy models, it seems worth exploring approaches to create models that are more explainable and steerable by design, built on well-understood components and rigorous foundations.
There are not many agendas that try to provide an end-to-end solution to alignment, but here are some of them.
Open Agency Architecture, by Davidad. Basically, create a highly realistic simulation of the world using future LLM that would code it. Then, define some security constraints that apply to this simulation. Then, train an AI on that simulation and use formal verification to make sure that the AI never does bad things. This proposal may seem extreme because creating a detailed simulation of the world is not easy, but this plan is very detailed and, if it works, would be a true solution to alignment and could be a real alternative to simply scaling LLMs. More information on this proposal is available in the appendix. Davidad is leading a program in ARIA to try to scale this research.
Provably safe systems: the only path to controllable AGI from Max Tegmark and Steve Omohundro. The plan puts mathematical proofs as the cornerstone of safety. An AI would need to be a Proof-Carrying Code, which means that it would need to be something like a PPL (and not just some deep learning). This proposal aims to make not only the AI but also the whole infrastructure safe, for example, by designing GPUs that can only execute proven programs.
Other proposals for a safe-by-design system include The Learning-Theoretic Agenda, from Vanessa Kossoy, and the QACI alignment plan from Tamsin Leake. The CoEm proposal from Conjecture could also be in this category.
Unfortunately, all of these plans are far from complete today.
These plans are safety agendas with relaxed constraints, i.e., they allow the AGI developer to incur a substantial alignment tax. Designers of AI safety agendas are cautious about not increasing the alignment tax to ensure labs implement these safety measures. However, the agendas from this section accept a higher alignment tax. For example, CoEm represents a paradigm shift in creating advanced AI systems, assuming you're in control of the creation process.
These plans would require international cooperation. For example, Davidad’s plan also includes a governance model that relies on international collaboration. You can also read the post “Davidad's Bold Plan for Alignment: An In-Depth Explanation — LessWrong,” which details more high-level hopes. Another perspective can be found in Alexandre Variengien’spost, detailing Conjecture's vision, with one very positive externality being a change in narrative.
Enhanced global coordination on AI development. To ensure that the advancement of AI benefits society as a whole, it's imperative to establish a global consensus on mitigating extreme risks associated with AI models. We should coordinate to avoid creating models with extreme risks until there is a consensus on how to mitigate these risks.
The trade-off between creating superhuman intelligence now or later. Of course, we can aim to develop an ASI ASAP. This could potentially solve cancer, cardiovascular diseases associated with aging, and even the problems of climate change. Maybe. The question is whether it's beneficial to aim to construct an ASI in this next decade, especially when the co-head of the alignment team, Jan Leike, suggests that the probability of doom is between 10 and 90%. It could be better to wait a few years so that the probability of failure drops to more reasonable numbers. It's important to make this trade-off public and to make a democratic and transparent choice.
Instead of building ASIs, we could focus on the development of specialized, non-agentic AI systems for beneficial applications such as medical research, weather forecasting, and materials science. These specialized AI systems can significantly advance their respective domains without the risks associated with creating highly advanced, autonomous AI. For instance, Alpha Geometry is capable of reaching the Gold level at the International Mathematical Olympiads. By prioritizing non-agentic models, we can harness the precision and efficiency of AI while avoiding the most dangerous failure modes.
The myth of inevitability. The narrative that humanity is destined to pursue overwhelmingly powerful AI can be deconstructed. History shows us that humanity can choose not to pursue certain technologies, such as human cloning, based on ethical considerations. A similar democratic decision-making process can be applied to AI development. By actively choosing to avoid the riskiest applications and limiting the deployment of AI in high-stakes scenarios, we can navigate the future of AI development more responsibly. This approach emphasizes precaution, ethical responsibility, and collective well-being, steering clear of the metaphorical "playing with fire" in AI advancements. This is what we call the myth of inevitability.
The likely result of humanity facing down an opposed superhuman intelligence is a total loss. Valid metaphors include “a 10-year-old trying to play chess against Stockfish 15”, “the 11th century trying to fight the 21st century,” and “Australopithecus trying to fight Homo sapiens“.
The "shut it all down" position, as advocated by Eliezer Yudkowsky, asserts that all advancements in AI research should be halted due to the enormous risks these technologies may pose if not appropriately aligned with human values and safety measures [8].
According to Yudkowsky, the development of advanced AI, especially AGI, can lead to a catastrophic scenario if adequate safety precautions are not in place. Many researchers are aware of this potential catastrophe but feel powerless to stop the forward momentum due to a perceived inability to act unilaterally.
The policy proposal entails shutting down all large GPU clusters and training runs, which are the backbones of powerful AI development. It also suggests putting a limit on the computing power anyone can use to train an AI system and gradually lowering this ceiling to compensate for more efficient training algorithms.
The position argues that it is crucial to avoid a race condition where different parties try to build AGI as quickly as possible without proper safety mechanisms. This is because once AGI is developed, it may be uncontrollable and could lead to drastic and potentially devastating changes in the world.
He says there should be no exceptions to this shutdown, including for governments or militaries. The idea is that the U.S., for example, should lead this initiative not to gain an advantage but to prevent the development of a dangerous technology that could have catastrophic consequences for everyone.
It's important to note that this view is far from consensual, but the "shut it all down" position underscores the need for extreme caution and thorough consideration of potential risks in the field of AI.
Systemic risks
Recap on some systemic risks introduced or exacerbated by AI:
🔒 Value lock-in: E.g., stable totalitarian dictators using AI to maintain their power.
😔 Mental health concerns: For example, large-scale unemployment due to automation could lead to mental health challenges.
🔥 Societal alignment: AI could intensify climate change issues and accelerate the depletion of essential resources by driving rapid economic growth.
🚫 Disempowerment: AI systems could make individual choices and agency less relevant as decisions are increasingly made or influenced by automated processes.
There are no clear solutions to those systemic risks, but here are some considerations.
Exacerbated Biases: There is already a large body of literature on reducing bias [s]. Unfortunately, many developers and ML researchers dismiss those problems. The first step, which is not simple, is recognizing those problems. Developers must be aware that biases can arise at many stages of the AI development process, from data collection to model training and deployment. Then mitigating those biases is not impossible, and best practices exist. The main techniques are data preprocessing and filtering, diversifying the data, and instruction tuning. Those techniques are pretty subtle and are not perfect, but they are solid baselines.
Value Lock-in: One of the most concerning risks posed by AI is the potential for stable totalitarian dictators to use the technology to maintain their power. It's not simple to mitigate this risk. In some ways, we already live in a kind of value lock-in. One solution could be avoiding the concentration of advanced AI capabilities in the hands of a few powerful actors. Instead, we should work towards a future where AI is developed openly, and its benefits are widely distributed through the help, for example, of an international organisation. This could help prevent authoritarian lock-in. Another important aspect is preserving human agency by maintaining the ability for humans to meaningfully steer the future trajectory of AI systems rather than ceding all control to automated optimization processes. But this is easier said than done.
Manage Mental Health Concerns: The rapid development and deployment of AI systems could significantly affect mental health. As AI becomes more capable and ubiquitous, it may displace many jobs, increasing unemployment, financial stress, and feelings of purposelessness. While the link between automation, job loss, and mental health may seem indirect and beyond the scope of AI development, it is still essential to consider the potential impacts since this could affect almost all of us. If a student's main activity, for example an art for which the student has been training during their whole studies, is automated overnight, their mental health may suffer for a while. Unemployment is associated with adverse mental health outcomes long after initial job loss occurs [8]. To mitigate these risks, we can prioritize mental health support and resources alongside the development of AI. This could include investing in education and retraining programs to help workers adapt to the changing job market, funding research into AI's mental health impacts, and developing targeted interventions. There is also a large amount of scientific literature on mental health that should be made accessible.
Additionally, the use of AI in social media and other online platforms can exacerbate issues like addiction, anxiety, and depression. A 2021 whistleblower report revealed that the company's own internal research showed that Instagram was detrimental to the mental health of teenage girls, worsening body image issues and suicidal thoughts. Despite this knowledge, they allegedly prioritized profits over making changes to mitigate these harms. A first step to solving those problems could be acknowledging the problem and committing to finding solutions, even if this means less profit.
Societal Alignment: To address the potential misalignment between AI systems and societal values and to avoid scenarios like capitalism on steroids during which a system consumes all the resources and exacerbates climate change [s], a partial solution could be to internalize negative externalities by, for example, implementing a carbon tax. Again, easier said than done. This is why fostering multidisciplinary collaboration between AI developers, economists, and other domain experts is essential in this process. But ultimately, we should debate the extent of automation that we want in society, and those are political and societal choices, not just AI technical difficulties.
Disempowerment and enfeeblement: As AI systems become more advanced and integrated into our lives, we must ensure that humans remain empowered and maintain agency. While tools like GPT-4 may offer short-term benefits, the next generation of those systems also raises concerns about the potential for long-term human disempowerment. To address this risk, we must actively work towards developing AI systems that augment and support human capabilities rather than replacing them entirely. There needs to be a debate about the limits of what we allow ourselves to do as a society and what we don't allow ourselves to do. It's what we decide to go for and how far we're willing to go with fully automated societies.
In summary, addressing the systemic risks posed by AI is not easy. It requires ongoing, multidisciplinary collaboration and solving complex coordination games. The fact that responsibility for the problem is so diverse makes it difficult to make the solutions actionable. Acknowledging the problems is perhaps the most critical step in many of the above issues.
Transversal Solutions
Figure: An illustration of a framework that we think is robustly good to manage risks.
AI Risks are too numerous and too heterogeneous. To address these risks, we need an adaptive framework that can be robust and evolve as AI advances.
Strategy A: AI Governance
The pursuit of AI advancement, much like the nuclear arms race of the Cold War era, represents a trade-off between safety and the competitive edge nations and corporations seek for power and influence. This competitive dynamic increases global risk, underscoring the need for deliberate governance and the redesign of economic incentives to prioritize long-term safety over short-term gains.
Effective AI governance aims to achieve two main objectives: a) time and resources for solution development, and Ensuring sufficient time and resources are allocated for identifying and implementing safety measures and b) enhanced coordination: Increasing the likelihood of widespread adoption of safety measures through global cooperation. AI risks are multifaceted, necessitating regulations that encourage cautious behavior among stakeholders and timely responses to emerging threats.
Designing better incentives:
Windfall clauses: Implementing agreements to share the profits between the different labs generated from AGI would mitigate the race to AI supremacy by ensuring collective benefit from individual successes. [Footnote: For example, in the pharmaceutical industry for drug development, companies sometimes enter into co-development and profit-sharing agreements to share the risks and rewards of bringing a new drug to market. For example, in 2014, Pfizer and Merck entered into a global alliance to co-develop and co-commercialize an anti-PD-L1 antibody for the treatment of multiple cancer types.]
Rethinking AGI labs governance: It is important to examine the governance structures of AGI labs. For example, being non-profit and having a mission statement that makes it clear that the goal is not to make the most money, but to ensure that the development of AI benefits all of humanity, is an important first step.
Centralized development of high-risk AI: For example, Yoshua Bengio et al. propose creating a secure facility akin to CERN for physics, where the development of potentially dangerous AI technologies can be tightly controlled [s]. This measure is highly non consensual.
Legal liability for AI developers: Establishing clear legal responsibilities for AI developers regarding misuse or failures can foster safer development practices.
Preventing the development of dangerous AI:
Moratoriums and regulations: Implementing temporary halts on the development of high-risk AI systems and enforcing legal frameworks, like the EU AI Act, to regulate or prohibit certain AI capabilities.
Controlling Access and Replication: Limiting the distribution and replication of powerful AI systems to prevent widespread misuse.
Maintaining human control:
Meaningful human oversight: Ensuring AI systems, especially those involved in critical decision-making processes, operate under human supervision to prevent irreversible consequences.
In conclusion, mitigating AI's risks requires a multifaceted approach combining governance, public engagement, economic incentives, legal measures, and promoting a global safety culture. By fostering international cooperation and prioritizing safety and ethical considerations in AI development, humanity can navigate the challenges posed by advanced AI technologies and harness their potential for the greater good.
For more information, see the chapters on AI Governance.
Strategy B: Organizational safety
Accidents Are Hard to Avoid, even when the incentive structure and governance try to ensure that there will be no problems. For example, even today, there are still accidents in the aerospace industry.
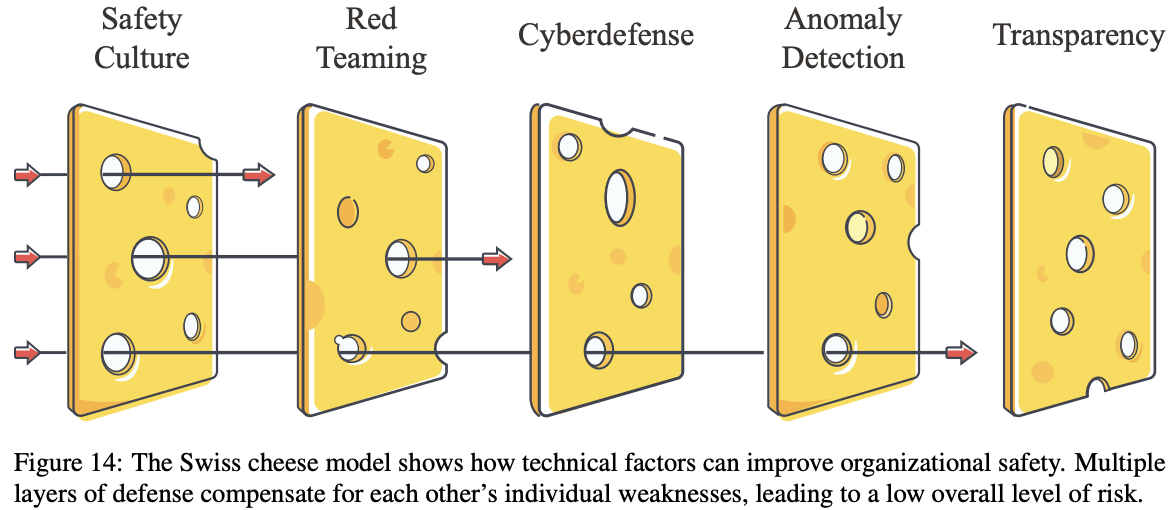
To solve those problems, we advocate for a Swiss cheese model — no single solution will suffice, but a layered approach can significantly reduce risks. The Swiss cheese model is a concept from risk management, widely used in industries like healthcare and aviation. Each layer represents a safety measure, and while individually they might have weaknesses, collectively they form a strong barrier against threats. Organizations should also follow safe design principles, such as defense in depth and redundancy, to ensure backup for every safety measure, among others.
Many solutions can be imagined to reduce those risks, even if none is perfect. The first step could be commissioning external red teams to identify hazards and improve system safety. This is what OpenAI did with METR to evaluate GPT-4. However AGI labs also need an internal audit team for risk management. Just like banks have risk management teams, this team needs to be involved in the decision processes, and key decisions should involve a chief risk officer to ensure executive accountability. One of the missions of the risk management team could be, for example, designing pre-set plans for managing security and safety incidents.
Accidents could also arise during training before the deployment. Sporadically, this can also be an error sign or a bug [s]. To avoid accidents during training, the training should also be responsible.Model evaluation for extreme risks, which was written by researchers from OpenAI, Anthropic, and DeepMind, lays out a good baseline strategy for what needs to be done before training, during training, before deployment, and after deployment.
Figure from [s], a workflow for training and deploying a model responsibly.
Strategy C: Safety Culture
AI safety is a socio-technical problem that requires a socio-technical solution. As such, the resolution to these challenges cannot be purely technical. Safety culture is crucial for numerous reasons. At the most basic level, it ensures that safety measures are at least taken seriously. This is important because a disregard for safety can lead to the circumvention or rendering useless of regulations, as is often seen when companies that don't care about safety face audits [4].
The challenge of industry-wide adoption of technical solutions. Proposing a technical solution is only the initial step toward addressing safety. A technical solution or set of procedures needs to be internalized by all members of an organization. When safety is viewed as a key objective rather than a constraint, organizations often exhibit leadership commitment to safety, personal accountability for safety, and open communication about potential risks and issues [1].
Reaching the standards of the aerospace industry. In aerospace, stringent regulations govern the development and deployment of technology. For instance, an individual cannot simply build an airplane in their garage and fly passengers without undergoing rigorous audits and obtaining the necessary authorizations. In contrast, the AI industry operates with significantly fewer constraints, adopting an extremely permissive approach to development and deployment, allowing developers to create and deploy almost any model. These models are then integrated into widely used libraries, such as Hugging Face, and those models can then proliferate with minimal auditing. This disparity underscores the need for a more structured and safety-conscious framework in AI. By adopting such a framework, the AI community can work towards ensuring that AI technologies are developed and deployed responsibly, with a focus on safety and alignment with societal values.
Safety culture can transform industries. Norms about trying to be safe can be a powerful way to notice and discourage bad actors. In the absence of a strong safety culture, companies and individuals may be tempted to cut corners, potentially leading to catastrophic outcomes [4]. Capabilities often trade off with safety. The adoption of safety culture in the aerospace sector has transformed the industry, making it more attractive and generating more sales. Similarly, an ambitious AI safety culture would require the establishment of a large AI security industry (a neologism inspired by the cybersecurity industry).
If achieved, safety culture would be a systemic factor that prevents AI risks. Rather than focusing solely on the technical implementation of a particular AI system, attention must also be given to social pressures, regulations, and safety culture. This is why engaging the broader ML community that is not yet familiar with AI Safety is critical [6].
How to concretely increase public awareness and safety culture?
Open letters: Initiatives like open letters, similar to the one from the Future of Humanity Institute [s], can spark public debate on AI risks.
Safety culture promotion: Advocating for a culture of safety among AI developers and researchers to preemptively address potential risks, for example by organizing internal training on safety. For example, internal training for cybersecurity is already common for some companies. Opening AI safety courses in universities and training future ML practitioners is also important.
Building consensus: Create a global AI risk assessment body, similar to the IPCC for climate change, to standardize and disseminate AI safety findings.
Conclusion
The field of AI safety is still in its early stages, but it is rapidly evolving to address the complex challenges posed by the development of increasingly powerful AI systems. This chapter has provided an overview of the current solutions landscape, highlighting the key strategies and approaches being explored to mitigate risks associated with AI misuse, alignment, and systemic impacts.
Addressing AI misuse involves strategies such as restricting access to high-risk models through monitored APIs, accelerating the development of defensive technologies, and establishing legal frameworks and social norms to discourage harmful applications. Alignment of AGI remains a formidable challenge, with current techniques proving fragile and insufficient for ensuring robust alignment of highly capable systems. Researchers are exploring avenues such as automating alignment research, developing safe-by-design architectures, and fostering international cooperation to navigate the path toward aligned superintelligence.
Systemic risks introduced or exacerbated by AI – such as exacerbated biases, value lock-in, mental health concerns, and societal misalignment – require a multifaceted approach that combines technical solutions with governance frameworks, economic incentives, and public engagement. Transversal solutions, including effective AI governance, organizational safety practices, and the cultivation of a strong safety culture, are essential for creating a robust and adaptive framework to manage the diverse risks associated with AI development.
As the field of AI safety continues to mature, it is crucial to recognize that no single solution will suffice. A layered, "Swiss cheese" approach that combines multiple strategies and engages stakeholders across disciplines is necessary to navigate the challenges ahead. Ongoing research, collaboration, and public discourse will be vital in shaping the trajectory of AI development to ensure that the transformative potential of these technologies is harnessed for the benefit of humanity while mitigating existential risks.
The path forward requires a collective commitment to prioritizing safety, ethics, and alignment in AI development. By fostering a culture of responsibility, investing in research and governance frameworks, and engaging in proactive risk management, we can work towards a future in which AI systems are powerful allies in solving global challenges and improving the human condition.
Thanks to Markov and Jeanne Salle and the participants of ML4Good for useful feedback.
We develop a technique to try and detect if a NN is doing planning internally. We apply the decoder to the intermediate representations of the network to see if it’s representing the states it’s planning through internally. We successfully reveal intermediate states in a simple Game of Life model, but find no evidence of planning in an AlphaZero chess model. We think the idea won’t work in its current state for real world NNs because they use higher-level, abstract representations for planning that our current technique cannot decode. Please comment if you have ideas that may work for detecting more abstract ways the NN could be planning.
Idea and motivation
To make safe ML, it’s important to know if the network is performing mesa optimization, and if so, what optimization process it’s using. In this post, I'll focus on a particular form of mesa optimization: internal planning. This involves the model searching through possible future states and selecting the ones that best satisfy an internal goal. If the network is doing internal planning, then it’s important the goal it’s planning for is aligned with human values. An interpretability technique which could identify what states it’s searching through would be very useful for safety. If the NN is doing planning it might represent the states it’s considering in that plan. For example, if predicting the next move in chess, it may represent possible moves it’s considering in its hidden representations.
We assume that NN is given the representation of the environment as input and that the first layer of the NN encodes the information into a hidden representation. Then the network has hidden layers and finally a decoder to compute the final output. The encoder and decoder are trained as an autoencoder, so the decoder can reconstruct the environment state from the encoder output. Language models are an example of this where the encoder is the embedding lookup.
Our hypothesis is that the NN may use the same representation format for states it’s considering in its plan as it does for the encoder's output. Our idea is to apply the decoder to the hidden representations at different layers to decode them. If our hypothesis is correct, this will recover the states it considers in its plan. This is similar to the Logit Lens for LLMs, but we’re applying it here to investigate mesa-optimization.
A potential pitfall is that the NN uses a slightly different representation for the states it considers during planning than for the encoder output. In this case, the decoder won’t be able to reconstruct the environment state it’s considering very well. To overcome this, we train the decoder to output realistic looking environment states given the hidden representations by training it like the generator in a GAN. Note that the decoder isn’t trained on ground truth environment states, because we don’t know which states the NN is considering in its plan.
We consider an NN trained to predict the number of living cells after the Nth time step of the Game of Life (GoL). We chose the GoL because it has simple rules, and the NN will probably have to predict the intermediate states to get the final cell count. This NN won’t do planning, but it may represent the intermediate states of the GoL in its hidden states. We use an LSTM architecture with an encoder to encode the initial GoL state, and a “count cells NN” to output the number of living cells after the final LSTM output. Note that training the NN to predict the number of alive cells at the final state makes this more difficult for our method than training the network to predict the final state since it’s less obvious that the network will predict the intermediate states. The number of timesteps of the LSTM isn’t necessarily the same as the number of GoL timesteps. If the number of timesteps are different, the LSTM may skip one of the timesteps in its representation. Alternatively, the LSTM could output the same time step twice. The thought bubbles in this diagram show the states we’re hypothesizing the network will represent.
We also train the count cells NN to count the number of live cells in the first state given the encoder output. This encourages the NN to use the same representation for the first and last states. We train the decoder we use for interpretability to reconstruct the initial state given the encoder output. The decoder isn’t trained to predict the final GoL state.
During inference, we feed the output of the LSTM at each timestep to the decoder. We also train the decoder with the GAN loss to produce a reasonable intermediate representation.
We measure the correlation between the ground truth GoL states, and the states reconstructed by applying the decoder to the intermediate LSTM outputs. We exclude the initial GoL state from our evaluation metric because the decoder was trained on it. We do count the final GoL state in the metric as the decoder was never trained to predict it.
GoL timesteps
LSTM timesteps
Mean correlation
Number of runs
2
2
0.79
8
2
3
0.81
5
2
4
0.73
9
3
2
0.93
7
3
3
0.76
8
3
4
0.76
4
4
3
0.86
3
For each configuration of architecture and GoL timesteps, we train the network multiple times with different random seeds, and average the metric result together. The high correlation with the ground truth GoL states indicates that this works well in this simple setup. In abolition studies we find that the GAN objective helps because without it, the predicted states are between alive and dead.
Here is an example of predicted an ground truth GoL states which get a correlation of .87:
Each column is a timestep of the GoL or the LSTM. The first column always matches because the decoder was trained to reconstruct it. In this case, the 2nd and 3rd predicted states match the 2nd GoL state closely, and the 4th predicted state matches the final GoL state somewhat.
Alpha Chess experiments
We also try the technique on an alpha zero model trained on chess since that’s a more practical setting. We try to recover the states the network may be considering when planning. Previous work also interprets the alpha chess model. Alpha chess is trained to predict the value and policy with two separate heads. We use a pretrained alpha chess model and leave the weights unchanged. We train a decoder to predict the current state after the first conv layer. We also train the decoder to predict the state of the board after the predicted move is executed given the final backbone layer. This is the last layer before the value and policy heads split.
We apply the decoder to the outputs of the other intermediate layers to see if they reconstruct states the NN may be considering. Our analysis did not reveal consistent representations of valid moves within the intermediate layers. Without the GAN loss, the decoder often produced boards that resembled the initial state, but with seemingly random pieces inserted or removed. We sometimes found layers which decoded to valid queen moves, but this wasn’t consistent. Using the GAN loss didn’t noticeably help.
These are some board states reconstructed from various layers of the NN without the GAN loss. The board on the right is the state given to the NN. The state on the left is the reconstructed state from the intermediate layer. The letters represent pieces. The highlights show the difference from the current state. In the first example, the rook disappears, and a queen appears.
This one shows the valid queen moves:
The technique not consistently finding valid moves could either mean that search isn’t happening in the network, or that the technique simply failed to find it.
Conclusion
The technique works in simple cases like the GoL, but didn’t find search happening in Alpha Chess. We think it’s likely that NNs do planning using a higher level representation than they use to represent their inputs. The input representation has to be detailed because the network will need to know the precise location of the pieces in chess, or the enemies in a game in order to choose the best action. However, when planning, the NN can use a higher level representation. For example, a human planning their day might consider actions like “make breakfast”, “drive to work”, “write a blog post”, but won’t consider things at the level of detail required to reconstruct their visual inputs. Similarly, a chess model might plan in terms of strategic objectives like 'attack the kingside' or 'develop the queen,' rather than representing the position of every piece. For this reason, we think the idea is unlikely to work to uncover NNs doing planning in its current state. We welcome suggestions on how to modify our technique to better detect more abstract ways the NN could be planning, or ideas for alternative approaches to studying internal planning in NNs.
OpenAI released draft guidelines for how it wants the AI technology inside ChatGPT to behave—and revealed that it’s exploring how to ‘responsibly’ generate explicit content.
Demis Hassabis, Google’s artificial intelligence chief, says the AlphaFold software that revolutionized the study of proteins has received a significant upgrade that will advance drug development.
What’s going on with deep learning? What sorts of models get learned, and what are the learning dynamics? Singular learning theory is a theory of Bayesian statistics broad enough in scope to encompass deep neural networks that may help answer these questions. In this episode, I speak with Daniel Murfet about this research program and what it tells us.
In this transcript, to improve readability, first names are omitted from speaker tags.
Filan:
Hello, everybody. In this episode, I’ll be speaking with Daniel Murfet, a researcher at the University of Melbourne studying singular learning theory. For links to what we’re discussing, you can check the description of this episode and you can read the transcripts at axrp.net. All right, well, welcome to AXRP.
Murfet:
Yeah, thanks a lot.
What is singular learning theory?
Filan:
Cool. So I guess we’re going to be talking about singular learning theory a lot during this podcast. So, what is singular learning theory?
Murfet:
Singular learning theory is a subject in mathematics. You could think of it as a mathematical theory of Bayesian statistics that’s sufficiently general with sufficiently weak hypotheses to actually say non-trivial things about neural networks, which has been a problem for some approaches that you might call classical statistical learning theory. This is a subject that’s been developed by a Japanese mathematician, Sumio Watanabe, and his students and collaborators over the last 20 years. And we have been looking at it for three or four years now and trying to see what it can say about deep learning in the first instance and, more recently, alignment.
Filan:
Sure. So what’s the difference between singular learning theory and classical statistical learning theory that makes it more relevant to deep learning?
Murfet:
The “singular” in singular learning theory refers to a certain property of the class of models. In statistical learning theory, you typically have several mathematical objects involved. One would be a space of parameters, and then for each parameter you have a probability distribution, the model, over some other space, and you have a true distribution, which you’re attempting to model with that pair of parameters and models.
And in regular statistical learning theory, you have some important hypotheses. Those hypotheses are, firstly, that the map from parameters to models is injective, and secondly (quite similarly, but a little bit distinct technically) is that if you vary the parameter infinitesimally, the probability distribution it parameterizes also changes. This is technically the non-degeneracy of the Fisher information metric. But together these two conditions basically say that changing the parameter changes the distribution changes the model.
And so those two conditions together are in many of the major theorems that you’ll see when you learn statistics, things like the Cramér-Rao bound, many other things; asymptotic normality, which describes the fact that as you take more samples, your model tends to concentrate in a way that looks like a Gaussian distribution around the most likely parameter. So these are sort of basic ingredients in understanding how learning works in these kinds of parameterized models. But those hypotheses do not hold, it’s quite easy to see, for neural networks. I can go into more about why that is.
So the theorems just don’t hold. Now, you can attempt to make use of some of these ideas anyway, but if you want a thoroughgoing, deep theory that is Bayesian and describes the Bayesian learning process for neural networks, then you have to be proving theorems in the generality that singular learning theory is. So the “singular” refers to the breaking of these hypotheses. So the fact that the map from parameters to models is not injective, that means, in combination with this other statement about the Fisher information metric, that if you start at a neural network parameter, then there will always be directions you can vary that parameter without changing the input/output behavior, without changing the model.
Some of those directions are kind of boring, some of them are interesting, but that’s what singular learning theory is about: accommodating that phenomenon within the space of neural networks.
Filan:
The way I’d understood it is that this basically comes down to symmetries in the neural network landscape. You can maybe scale down this neuron and scale up this neuron, and if neurons are the same, it doesn’t matter. But not only are there symmetries, there are non-generic symmetries.
Murfet:
Correct. Yeah.
Filan:
Because if there were just some symmetries, then maybe you could mod out by the symmetries… If you looked at the normal direction to the space at which you could vary things, then maybe that would be fine. So the way I’ve understood it is that there are certain parameter settings for neural networks where you can change it one way or you can change it another way, but you can’t change it in both directions at once. And there are other parameter settings where you can only change it in one of those two ways. So the fact that you can’t do them both at once means it’s not a nice, smooth manifold. And the fact that it’s different at different places means that it’s not this generic thing over the whole space. Some models are more symmetric than others and that ends up mattering.
Murfet:
Yeah, I would say that’s mostly correct. I would say the word ‘symmetry’ is really not… I think I would also at a high level maybe use this word to a first approximation in explaining what’s going on, but it’s really not a sufficient concept. But yeah, it’s good to distinguish the kind of boring generic symmetries that come from the non-linearities. So in some sense, that’s why you can just look at a neural network and know that it’s singular because of these symmetries, like the ReLU scaling up the input and scaling down the output weights respectively will not change the behavior of the network. So that’s an obvious scaling symmetry, and that means that it’s degenerate and therefore a singular model.
But if that was all there was, then I agree: somehow that’s a boring technical thing that doesn’t seem like you really need, from a point of view of understanding the real phenomena, to care about it too much. But the reason that SLT [singular learning theory] is interesting is that, as you say, different regions of parameter space, you could say have different kinds of symmetries as a reflection of the different ways qualitatively in which they’re attempting to model the true distribution. But this other thing you mentioned, about being able to move in different directions, that’s not really symmetry so much as degeneracy.
So we could go more into conceptually why different regions or different kinds of solutions might have different kinds of degeneracy, but at a high level that’s right. Different kinds of solutions have different kinds of degeneracy, and so being able to talk about different kinds of degeneracy and how they trade off against one another, and why Bayesian learning might prefer more or less degenerate kinds of models, is the heart of SLT.
Filan:
Sure. Before we go into that, what do you mean by “degeneracy”?
Murfet:
Degeneracy just refers to this failure of the map from parameters to models to be injective. So “a degeneracy” would just mean a particular kind of way in which you could vary the neural network parameter, say in such a way that the input/output map doesn’t change. And as you were just mentioning, you might have, at one point, two or more essentially different ways in which you could vary the parameter without changing the loss function. And that is by definition what geometry is. So what I’m describing there with my hand is the level set of the loss function. It might be the minimal level set or some other level set, but if we’re talking about multiple ways I can change the neural network parameter without changing the loss, then I’m describing the configuration of different pieces of the level set of the loss function at that point. And that’s what geometry is about.
Filan:
Sure. You mentioned that singular learning theory, or SLT for short, is very interested in different kinds of degeneracies. Can you tell us a little bit [about] what are the kinds of degeneracies, what different kinds of degeneracies might we see maybe in deep learning? And why does the difference matter?
Murfet:
I think it’s easier to start with a case that isn’t deep learning, if that’s all right. Deep learning jumps straight into the deep end in terms of… and it’s also the thing which we understand least, perhaps. But if you imagine the easiest kind of loss functions… and when I say loss function, I typically mean “population loss”, not the empirical loss from a fixed dataset of finite size, but the average of that of all datasets. So that’s somehow the theoretical object whose geometry matters here, so I’ll flag that, and there’s some interesting subtleties there.
So in a typical case, in a regular statistical setting - not neural networks, but linear regression or something - the population loss looks like a sum of squares, so just a quadratic form. And there, minimizing it - I mean maybe with some coefficients, the level sets are ellipses - then the learning process just looks like moving down that potential well to the global minimum. And that’s kind of all that’s happening. So in that case, there’s no degeneracy. So there’s just one global minimum and you can’t vary it at all and still have zero loss.
A more interesting case would be where: suppose you have 10 variables, but a sum of eight squares, so x1² through x8². And then if you minimize that, well, you’ve still got two free parameters, so there’s a two-dimensional space of global minima of that function. Now imagine a population loss, and let’s only care about local minima, which has many local minima at various heights of the loss, each of which use different numbers of variables. So we suppose, for instance, that the global minimum maybe uses all 10, but then there’s a level set a bit higher than that that uses only nine squares, and a level set a bit higher than that that uses only eight squares. And so then those have different amounts of degeneracy.
So you have different points in the parameter space, loss landscape, where local minima have different degrees of degeneracy. And so then you can think about the competition between them in terms of trading off between preference for degeneracy versus preference for loss. And then we’re getting into key questions of if you’re a Bayesian, what kind of solution you prefer in terms of accuracy versus degeneracy.
Filan:
And I guess this gets to this object that people talk about in singular learning theory called the “learning coefficient”. Can you tell us a little bit about what the learning coefficient is?
Murfet:
In the case I was just describing, it’s easy to say what the learning coefficient is. There’s a distinction between global learning coefficient… Everything I say about SLT, more or less, is material that was introduced by Watanabe and written about in hisbooks, and at some point, I guess we’ll talk about our contributions more recently. But mostly what I’m describing is not my own work, just to be clear.
So I’ll mostly talk about the local learning coefficient, which is a measure of degeneracy near a point in parameter space. If I take this example I was just sketching out: you imagine the global minimum level set and then some higher level sets. And I said that the population loss near the global minimum looked like a sum of 10 squares. And so the local learning coefficient of that would just be 10/2, so a half times the number of squares that you used.
So if there was a level set that had used only eight squares, then that’s degenerate, because you have two free directions, so it’s not a single isolated minimum, but rather a sort of two-dimensional plane of minimum. And each point of that two-dimensional plane would, because it locally looks like a sum of eight squares, have 8/2 as its local learning coefficient and so on. So if you use D’ squares in the local expression of your population loss, then your local learning coefficient is D’/2. That’s not how it’s defined: it has a definition, which we could get into various different ways of looking at it, but that’s what it cashes out to in those examples.
Filan:
Sure. I guess the way to think about this local learning coefficient is that when it’s lower, that’s a solution that’s more degenerate. And the way I gather Bayesian inference works is that it tries to have both a low loss and also a low local learning coefficient. Does that sound right?
Murfet:
Yep.
Filan:
An image I often see in discussions of singular learning theory is people drawing doodles of trefoils and figure eights and maybe a circle to throw in there. The thing I often hear (as a caricature) is: initially you stay around the trefoil for a while, this is where you put your posterior mass, until at some point you get enough data and then you start preferring this figure eight, and then you get even more data and then you start preferring this circle, which has maybe even lower loss. So as you go down, maybe you get better loss, let’s just say, but the local learning coefficient is going to increase and therefore get worse.
Murfet:
Maybe I’ll caveat that a little: the local learning coefficient is increasing, so you’re accepting a more complex solution in exchange for it being more accurate.
Phase transitions
Filan:
Yeah. So that’s the very basic idea of singular learning theory. Why does it matter? What are the important differences between the singular learning theory picture and the classical statistical learning theory picture?
Murfet:
In what context? Statistical learning theory in general, deep learning theory, alignment, or all three in that order?
Filan:
Maybe all three in that order. I think I want to put off the discussion of alignment relevance for a little bit later until we just understand what’s going on with this whole thing.
Murfet:
Okay. Yeah, I guess I didn’t actually come back to your question about the local learning coefficient in neural networks from earlier, but I think the cartoon in terms of sums of squares might still suffice for the moment.
If we talk about statistical learning theory in machine learning or deep learning in general, I think the main high-level conceptual takeaway from singular learning theory when you first encounter it should be that the learning process in Bayesian statistics really is very different for singular models. So let me define what I mean by “learning process”.
When we say “learning process” in deep learning, we tend to mean training by stochastic gradient descent. And what I’m saying is maybe related to that, but that’s a tricky point, so let me be clear that in Bayesian statistics, the “learning process” refers to: as you see more data, you change your opinion about what the relative likelihood of different parameters is. So you see more data, some parameters become ruled out by that data because they don’t give that data high probability, whereas other parameters become more likely. And what I’m describing is the Bayesian posterior, which assigns a probability to each parameter according to the data.
And so as you see more samples… I mean, if you’ve seen very few samples, you really have no idea which parameters are correct, so the posterior is very diffuse and will change a lot as you see more samples because you just are very ignorant. But asymptotic normality and regular statistical learning theory says that as you see more samples, that process starts to become more regular and concentrate around the true parameter in a way that looks like a Gaussian distribution.
So that’s in some sense a very simple process. But in singular models, that is not what happens, at least that’s not what’s predicted to happen by the theory. Until relatively recently, I think we didn’t have many very compelling examples of this in practice. But what the theory says is what you were describing earlier, that the Bayesian posterior should kind of jump as the trade-off between accuracy and complexity changes, which is a function of the number of samples. And those jumps move you from regions of qualitatively different solutions to other kinds of solutions, and then eventually maybe asymptotically to even choosing among perfect solutions depending on their complexity and then so on.
So there’s a very complicated, not very well-understood process underlying learning in Bayesian statistics for singular models, which as far as I know, Watanabe and his collaborators are the only people to ever really study. This is despite being somewhat old, in the sense that Watanabe and students and collaborators have been working on it for a while; it’s really not been studied in great depth outside of their group.
So [it’s] a very fundamental process in Bayesian statistics, relatively understudied, but arguably, at least if you take a Bayesian perspective, very central to how learning works in (say) neural networks, whether they’re artificial ones or even possibly biological ones.
So I think that’s the main thing. I mean, that’s not the only thing singular learning theory talks about. It’s not the only theoretical content, but I would say that’s the main thing I would want someone to know about the theory as it stands right now. The other thing is how that relates to generalization, but maybe I’ll pause there.
Filan:
Sure. Maybe we should talk about that a bit. I hear people talk about this with the language of phase transitions. And I think upon hearing this, people might say, “Okay, if you look at loss curves of big neural nets that are being trained on language model data, the loss kind of goes down over time, and it doesn’t appear to be stuck at one level and then suddenly jump down to another level and then be flat and then suddenly jump down.” We have things which kind of look like that in toy settings, like grokking, like the development of induction heads, but it doesn’t generically happen. So should we think of these phase transitions as being relevant to actual deep learning, or are they just a theoretical curiosity about the Bayesian theory?
Murfet:
Yeah, I think that’s a very reasonable question. I think a year ago, we ourselves were skeptical on this front. I think even in toy settings it wasn’t very clear that this theoretical prediction bears out. So maybe I’ll spend a moment to just be quite precise about the relationship between theory and practice in this particular place.
What the theory says is: asymptotically in N, the number of samples, a certain formula describing the posterior works, and then based on this formula, you can have the expectation that phase transitions happen. But in principle, you don’t know lower-order terms in the asymptotic, and there could be all sorts of shenanigans going on that mean that this phenomenon doesn’t actually occur in real systems, even toy ones. So theory on its own - I mean in physics or in machine learning or whatever - has its limits, because you can’t understand every ingredient in an asymptotic expansion. So even in toy settings, it was reasonable, I think, to have some skepticism about how common this phenomenon was or how important it was, even if the theory is quite beautiful.
Okay, so that aside, you go and you look in toy systems and you see this behavior, as we did, and then I think it’s reasonable to ask, “Well, okay, so maybe this happens in small systems, but not in large systems?” And indeed in learning curves, we don’t think we see a lot of structure.
So I’ll tell you what we know, and then what I think is going on. I should preface this by saying that actually we don’t know the answer to this question. So I think that it still remains unclear if this prediction about phases and phase transitions is actually relevant to very large models. We’re not certain about that. I would say there’s a reasonable case for thinking it is the case that it is relevant, but I want to be clear about what we know and don’t know.
Again, this is kind of an empirical question, because the theoretical situation under which phases and phase transitions exist… the theory stops at some point and doesn’t say much at the moment about this scale or that scale.
So what we know is that if you look at transformers around the scale of three million parameters, trained on language model datasets, you do see something like phases and phase transitions that basically describe… So again, what I’m about to describe is the learning process of training rather than seeing more samples. But the theoretical jump that we’re making here is to say, okay, if Bayesian statistics says certain kinds of structures in the model - if the theory says there should be qualitative changes in the nature of the way the posterior is describing which models are probable, if there are qualitative changes in that over the course of the Bayesian learning process, as you see more samples, then you might expect something similar when you go and look at seeing cumulatively more examples through the training process of stochastic gradient descent. But that is not a theoretically justified step at this point in some rigorous sense. That’s the kind of prediction you might make assuming some similarity between the learning processes, and then you can go in empirically and see if it’s true.
So if you go and look at language models at the scale of three million parameters… This is a recent paper that we did, Developmental Landscape of In-Context Learning. If you go and look at that, what you see [is] that the training process is divided into four or five stages, which have different qualitative content in a way that isn’t visible in the loss curve mostly.
Filan:
Yeah. I mean, it’s not obvious from the loss curve. It’s not like everybody already knew all the things that you guys found out.
Murfet:
Yeah, I would say that without these other results, if you looked at the loss curve and tried to tell the story about these little bumps, it would feel like tea leaf reading. But once you know that the stages are there, yes, you can look at the loss curve and sort of believe in certain features of them.
So I mean, there’s various details about how you think about the relationship between those stages and phases and phase transitions in a sense of SLT. But I would say that’s still a very small model, but not a toy model, in which you do see something like stage-wise development.
And there are independent reasons… People have independently been talking about stage-wise development in learning systems outside of SLT. So I would say that the SLT story and stage-wise development as a general framing for how structure arrives inside self-organizing learning processes, that dovetails pretty well. So I would say that, to come back to your question about structure in the loss curve, just because nothing’s happening in the loss curve doesn’t mean that there isn’t structure arriving in stages within a model. And our preliminary results on GPT-2 Small at 160 million parameters: at a high level it has stages that look pretty similar to the ones in the three million parameters.
Filan:
Interesting.
Murfet:
So here’s my guess for what’s going on. It’s true that in very large models, the system is learning many things simultaneously, so you won’t see very sharp transitions except possibly if they’re very global things: [e.g.] switching to in-context learning as a mode of learning seems like it affects most of the things that a system is learning, so a qualitative change at that scale, maybe you would guess actually is represented sort of at the highest level and might even be visible in the loss curve, in the sense that everything is coordinated around that. There’s before and after.
But many other structures you might learn, while they’re developing somewhere else in the model, it’s memorizing the names of U.S. presidents or something, which just has nothing to do with structure X, Y, Z. And so in some sense, the loss curve can’t possibly hit a plateau, because even if it’s hitting a critical point for these other structures X, Y, Z, it’s steadily making progress memorizing the U.S. presidents. So there can’t be clear plateaus.
So the hypothesis has to be something like: if there is stage-wise development, which is reflected by these phases and phase transitions, it’s in some sense or another localized, maybe localized to subsets of the weights and maybe localized in some sense to certain parts of the data distribution. So the global phases or phase changes which touch every part of the model and affect every kind of input are probably relatively rare, but that isn’t the only kind of phase, phase transition, stage to which Bayesian statistics or SLT could apply.
Filan:
Sure. Should I imagine these as being sort of singularities in a subspace of the model parameter space? The learning coefficient kind of picks them out in this subspace, but maybe not in the whole parameter space?
Murfet:
Yeah, that’s kind of what we’re thinking. These questions are pushing into areas that we don’t understand, I would say. So I can speculate, but I want to be clear that some parts of this we’re rather certain of: the mathematical theory is very solid, the observation of the correspondence between the theory and Bayesian phase transitions in toy models is empirically and theoretically quite solid. This question of what’s happening in very large systems is a deep and difficult question. I mean, these are hard questions, but I think that’s right, that’s the motivation for… One of the things we’re currently doing is what we call weight-restricted local learning coefficients. This basically means you take one part of the model, say, a particular head, you freeze all the other weights…
Let me just give a more formal setting. When we’re talking about the posterior and the local learning coefficient and so on, we imagine a space of parameters. So there’s D dimensions or something. Some of those directions in parameter space belong to a particular head, and I want to take a parameter that, at some point in training, has some values for all these heads, I mean, for all these different weights, and I want to freeze all but the ones in the head and then treat that as a new model. Now, my model is I’m not allowed to change those weights, but I’m allowed to change the weights involved in the head, and I can think about the Bayesian posterior for that model and I can talk about its local learning coefficient.
That involves perturbing the parameter nearby that particular coefficient, but in a way where you only perturb the weights involved in that part of the structure, say, that head, and you can define the complexity of that local learning coefficient. That’s what we call the weight-restricted local learning coefficient. And then the hypothesis would be that, if a particular part of the model is specializing in particular kinds of structure and that structure is developing, then you’ll be at a critical point for some kind of restricted loss that is referring only to those weights, and that would show up.
We haven’t talked about how the local learning coefficient is used to talk about phase transitions, but that’s the experimental way in which you’d attempt to probe whether some part of the model is doing something interesting, undergoing a phase transition separately from other parts of the model.
Filan:
Yeah, actually, maybe we should clarify that. How do you use the learning coefficient to figure out if a phase transition is happening?
Murfet:
It depends on your background which answer to this question is most pleasant. For physics-y people who know about free energy, they’re familiar with the idea that various derivatives of the free energy should do something discontinuous at a phase transition, and you can think about the local learning coefficient as being something like that. So that, if there is a phase transition, then you might expect this number to change rapidly relative to the way it usually changes.
If we just stick within a statistical learning theory frame, we were laying out this picture earlier of: as you see more samples, the Bayesian posterior is concentrated in some region of parameter space and then rapidly shifts to be concentrated somewhere else, and the local learning coefficient is a statistic of samples from the Bayesian posterior, so if the Bayesian posterior shifts, then this number will also shift. The expectation would be that, if you measure this number, which it turns out you can do from many experiments, if you see that number change in some significant way, then it is perhaps evidence that some qualitative change in the posterior has occurred. That’s a way of detecting phase transitions which is, if you take this bridge from Bayesian statistics to statistical physics, pretty well justified I would say.
Estimating the local learning coefficient
Filan:
Sure. A question about that: my understanding is that trying to actually measure the local learning coefficient involves taking a parameter setting and looking at a bunch of parameter settings nearby on all these dimensions that you could vary it, and measuring a bunch of properties, and this is the kind of thing that’s easy to do when you have a very low-dimensional parameter space corresponding to a small number of parameters. It seems like it’s going to be harder to do with a higher number of parameters in your neural networks. Just practically, how large a model can you efficiently measure local learning coefficient [for] at this time?
Murfet:
Yeah. That’s a good question. I think it’s tricky. Maybe this will be a bit of an extended answer, but I think it’ll be better if I provide some context. When we first started looking at SLT, myself and my colleague here at the University of Melbourne, Susan Wei, and some other people… This was before… believe it or not, today there are 10x the number of people interested in SLT than there were back when we started thinking about it. It was an extremely niche subject, very deep and beautiful, but somewhat neglected.
Our question at that time was exactly this question. The theory says the local learning coefficient - the “real log canonical threshold” is another mathematical name for it - the theory says this is a very interesting invariant, but it’s very unclear if you can accurately estimate it in larger models. A lot of the theoretical development [involved using] one PhD student to compute the RLCT of one model theoretically, and you need some hardcore algebraic geometry to do that, et cetera, et cetera. The way the subject sat, it wasn’t clear that you could really be doing this at scale because it seems to depend on having very accurate samples from the posterior via Markov Chain Monte Carlo sampling or something.
I admit, I was actually extremely pessimistic when we first started looking at it that there really would be a future in which we’d be estimating RLCTs, or local learning coefficients, of a hundred million parameter models. So that’s where I started from. My colleague Susan and my PhD student Edmund Lau decided to try SGLD, stochastic gradient Langevin dynamics, which is an approximate Bayesian sampling procedure based on using gradients, to see how it worked. There’s a step in estimating the local learning coefficient where you need samples from the posterior. As you’re describing, this is famously difficult for large dimensional complex models.
However, there is a possible loophole, which is that… I mean, I don’t believe that anybody has a technique, nor probably ever will, for understanding or modeling very accurately the Bayesian posterior of very large-scale models like neural networks. I don’t think this is within scope, and I’m skeptical of anybody who pretends to have a method for doing that, hence why I was pessimistic about estimating the LLC [local learning coefficient] at scale because it’s an invariant of the Bayesian posterior which seems to have a lot of information about it and I believe it’s hard to acquire that information. The potential loophole is that maybe the local learning coefficient relies on relatively robust signals in the Bayesian posterior that are comparatively easy to extract compared to knowing all the structure.
That seems to be the world that we are in. To answer your question, Zach Furman and Edmund Lau just recently had a pre-print out where, using SGLD, it seems you can get relatively accurate estimates for the local learning coefficient for deep linear networks: products of matrices and known nonlinearities at scales up to a hundred million parameters.
Filan:
A hundred million with an M?
Murfet:
With an M, yeah. One should caveat that in several ways, but yeah.
Murfet:
That’s right. This is a second paper, a followup to that. I forget the title. I think it’s Estimating Local Learning Coefficient at Scale. So we wrote that paper a couple of years ago now, I think, looking at defining the local learning coefficient - which is implicit in Watanabe’s work, but we made it explicit - and making the observation that you could use approximate sampling to estimate it and then studying that in some simple settings, but it remained very unclear how accurate that was in larger models.
Now, the reason it’s difficult to go and test that is because we don’t know the true local learning coefficient for very many models that can be increased in some direction of scale. We know it for one hidden layer tanh networks and things like that. But some recent, very deep, interesting work by Professor Miki Aoyagi gives us the true value of the local learning coefficient for deep linear networks, which is why Zach and Edmund studied those. This was an opportunity to see if SGLD is garbage or not for this purpose.
I should flag that despite… How should I say this? SGLD is a very well-known technique for approximate Bayesian posterior sampling. I think everybody understands that you should be skeptical of how good those posterior samples are in some sense. It might be useful for some purpose, but you shouldn’t really view it as a universal solvent for your Bayesian posterior sampling needs or something. Just using SGLD doesn’t magically mean it’s going to work, so I would view it as quite surprising to me that it actually gives accurate estimates at scale for deep linear networks.
Now, having said that, deep linear networks are very special, and they are less degenerate in some important ways than real neural networks with nonlinearities, et cetera, so don’t take me as saying that we know that local learning coefficient estimation gives accurate values of the local learning coefficient for language models or something. We have basically no idea about that, but we know it’s accurate in deep linear networks.
Okay, so then what is generalizable about that observation? I think it leads us to believe that maybe estimating the LLC, SGLD is actually not garbage for that. How good it is we still don’t know, but maybe this cheap posterior sampling is still good enough to get you something interesting. And then the other thing is that: well, what you observe in cases where you know the true values is that, when the model undergoes phase transitions which exist in deep linear networks, as many people have… Maybe not in those exact terms, but, stage-wise development in deep linear networks has been studied for quite a long time, and you can see that this local learning coefficient estimator which is measuring the complexity of the current parameter during the learning process does jump in the way you would expect in a phase transition, when deep linear networks go through these phase transitions.
Well, it had to, because we know theoretically what’s happening to the geometry there. Those jumps in the local learning coefficient in other models, like these 3 million parameter language models or GPT-2 Small… when you go and estimate the local learning coefficient, you see it change in ways that are indicative of changes in internal structure. Now, we don’t know that the absolute values are correct when we do that, and most likely they’re not, but I think we believe in the changes in the local learning coefficient reflecting something real to a greater degree than we believe in the absolute values being real. Still, theoretically, I don’t know how we would ever get to a point where we would know the local learning coefficient estimation was accurate in larger models absent really fundamental theoretical improvements that I don’t see coming in the near term, but that’s where we are at the moment.
Singular learning theory and generalization
Filan:
Fair enough. A while back, you mentioned the contributions of singular learning theory to understanding deep learning. There was something to do with phase transitions and there was also something to do with generalization, I think you mentioned. I want to ask you about that. Especially in the context of: I sometimes hear people say, “Oh, statistical learning theory says that model classes can have these parameters that have some degeneracy and that basically reduces their effective parameter count, and this just explains how generalization is possible.” This is the kind of story one can tell when one feels excitable, but it’s a bit more complicated. It’s going to depend on details of how these parameters actually translate into functions and what these degeneracies actually look like in terms of predictive models. What does singular learning theory tell us about generalization, particularly in the context of deep networks?
Murfet:
Yeah. This is subtle. On its face, [in] singular learning theory, the theorems describe relations between loss, local landscape geometry, this local learning coefficient, and generalization error in the Bayesian sense. In the Bayesian sense, what I mean by generalization error is the KL divergence between the true distribution and the predictive distribution.
Maybe I should say briefly what the latter is. If you’re trying to make a prediction, if you’re talking about a conditional distribution, a prediction of Y given X, and you look at all the parameters that you’ve got for modeling that relationship, and you’re given an input and you take the prediction from every single model parameterized by your parameter space, you weight it with the probability given to that particular model by the Bayesian posterior and you average them all in that way, that’s the Bayesian predictive distribution. [It’s] obviously radically intractable to use that object or find that object. It’s a theoretical object. That probability distribution is probably not one that’s parameterized by parameters in your parameter space, but you can cook it up out of models in your parameter space. The KL divergence between that and the truth is the Bayesian generalization error.
Filan:
The KL divergence just being a measure of how different probability distributions are.
Murfet:
Right. That seems like a very theoretical object. There’s a closely related object, the Gibbs generalization error, which puts some expectations in different orders which is closer to what people in machine learning mean by “test error” - taking a parameter and trying it out on some samples from the true distribution that weren’t used to produce that parameter. There’s the various subtleties there. SLT, strictly speaking, only says things about those kinds of generalization errors and the relationship between that and test error for a parameter produced by a single run of SGD - well, I don’t even know that that is a mathematical object actually (test error for a parameter after a single run), but you can do things like talk about, for some distribution of SGD runs, what’s the expected test error.
Then there’s a gap between that Bayesian story and what you mean by “test error” in deep learning. This gap hasn’t been very systematically addressed, but I’ll lay out some story about how you might bridge that eventually in order to answer your question. If you believe that the Bayesian learning process ends with a distribution of parameters that look something like the endpoints of SGD training, or at least close enough, that something like this average of SGD runs of the test error looks a bit like averaging over things in the Bayesian posterior of some generalization quantity that makes sense in the Bayesian theory, then you could maybe draw some connection between these two things.
That hasn’t been done. I don’t know if that’s true, because these questions about relations between the Bayesian posterior and SGD are very tricky and I don’t think they look like they’re going to get solved soon, at least in my opinion. There’s a gap there. That’s one gap. We just paper over that gap and just say, “Okay. Well, fine, let’s accept that for the moment and just treat the generalization error that SLT says things about as being the kind of generalization error that we care about. What does SLT say?”
Maybe I’ll insert one more comment about that relationship between test error in deep learning and Bayesian generalization error first. This is a bit of a tangent, but I think it’s important to insert here. Various people, when looking to explain the inductive bias of stochastic gradient descent, have hit upon a phenomenon that happens in deep linear networks and similar systems, which is a stage-wise learning where the model moves through complexity in an increasing way.
We think about in deep linear networks - or what’s sometimes called matrix factorization, where you’re trying to use a product of matrices to model a single linear transformation - people have observed that, if you start with a small initialization, the model starts with low rank approximations to the true linear transformation and then finds a pretty good low rank approximation and then takes a step to try and use linear transformations of one higher rank and so on, and moves through the ranks in order to try and discover a good model. Now, if you believe that, then you would believe that, if SGD training is doing that, then it will tend to find the simplest solution that explains the data, because it’s searching them starting with simpler ones and only going to more complicated ones when it needs to.
Now, theoretically, that’s only known to happen… I mean, I think it’s not known to happen in deep linear networks rigorously speaking, but there’s expectations of that, [and] empirically, that happens, and there’s some partial theory. Then it’s a big leap to believe that for general SGD training of general neural networks, so I think we really don’t know that that’s the case in general deep learning. Believing that is pretty similar to believing something about the Bayesian learning process moving through regions of parameter space in order of increasing complexity as measured by the local learning coefficient. In fact, that is exactly what’s happening in the deep linear networks.
The SLT story about moving through the parameter space and the Bayesian posterior undergoing phase transitions is exactly what’s happening in the deep linear networks. If you’re willing to buy that generalization from that corner of theory of deep learning to general behavior of neural networks, then I think you are in some sense already buying the SLT story to some degree, [the story] of how learning is structured by looking for increasingly complex solutions. All of those are big question marks from a theoretical point of view, I would say.
Putting that aside, what does SLT say about generalization? Well, it says that the asymptotic behavior of the generalization error as a function of the number of samples at the very end of training, let’s say, or the very end of the Bayesian learning process, looks like the irreducible loss plus a term that looks like lambda/N, where lambda is the local learning coefficient. If you take that irreducible loss over the other side, the difference between generalization error and its minimum value behaves like 1/n, is proportional to 1/n, and the constant of proportionality is the local learning coefficient. That’s the deep role of this geometric invariant, this measure of complexity in the description of generalization error in the Bayesian setting.
Now, what that says in deep learning… as I said, taking that first part of that bridge between the two worlds for granted, it would like to say something like: the test error when you’re looking at a particular region of parameter space is governed by the local learning coefficient, except that the relation between N and training is unclear. The exact way in which it governs test error is a function of how that bridge gets resolved. I think, at a technical level, it’s difficult to say much precise at the moment. I don’t think it’s impossible. It’s just that very few people are working on this and it hasn’t been getting enough attention to say more concrete things.
At a conceptual level, it says that - and this maybe starts to get into more interesting future work you can do taking the SLT perspective - but this relationship between the local learning coefficient and how that is determined by loss landscape geometry and generalization behavior, this is a very interesting link which I think is quite fundamental and interesting.
Filan:
That’s what I was inspired by: just this question of, suppose we believe the story of, we’re gradually increasing complexity as measured by the local learning coefficient in this model class: well, what does that actually say in terms of objects that I cared about before I heard of singular learning theory? What’s that telling me in terms of things I care about, of the behavior of these things?
Murfet:
It could tell you things like: suppose you know two solutions of your problem that are qualitatively different. You have a data-generating process and you can think about it in two different ways and, therefore, model it in two different ways. Potentially, if you could estimate the local learning coefficient or derive it or have some method of knowing that one is lower than the other, it could tell you things like one will be preferred by the Bayesian posterior.
Now, to the extent that that is related to what SGD finds, that might tell you that training is more likely to prefer some class of solutions to another class. Now, if those parameters are just very different, completely different solutions, somehow not nearby in parameter space, maybe it’s quite difficult to make the bridge between the way the Bayesian posterior would prefer one or the other and what training will do because, in that case, the relationship between training and these two parameters is this very global thing to do with the trajectory of training over large parts of the parameter space, and very difficult perhaps to translate into a Bayesian setting.
In cases where you have two relatively similar solutions, maybe you had a choice to make. So during the training process, you had one of two ways to take the next step and accommodate some additional feature of the true distribution, and those two different choices differed in some complexity fashion that could be measured by the local learning coefficient: one was more complex, but lowered the loss by so much, and the other one was simpler, but didn’t lower the loss quite as much. Then you could make qualitative predictions for what the Bayesian posterior would prefer to do, and then you could ask, “Are those predictions also what SGD does?” Either, theoretically, you could try and find arguments for why that is true, but it [also] gives you an empirical prediction you can go and test.
In this toy model of superposition work we did, SGD training does seem to do the thing that the Bayesian posterior wants to do. That’s very unclear in general, but it gives you pretty reasonable, grounded predictions that you might then go and test, which I think is not nothing. That would be, I think, the most grounded thing you’d do with the current state of things.
Filan:
I guess it suggests a research program of trying to understand which kinds of solutions do have a lower learning coefficient, which kinds of solutions have higher learning coefficients, and just giving you a different handle on the problem of understanding what neural network training is going to produce. Does that seem fair?
Murfet:
Yeah. I think, [for] a lot of these questions about the relation between the theory and practice, our perspective on them will shift once we get more empirical evidence. What I expect will happen is that these questions seem to loom rather large when we’ve got a lot of theory and not so much empirical evidence. If we go out and study many systems and we see local learning coefficients or restricted local learning coefficients doing various stage-wise things and they correspond very nicely to the structure that’s developing, as we can test independently with other metrics, then I think it will start to seem a little bit academic whether or not it’s provably the case that SGD training does the same thing as the Bayesian posterior just because this tool, which…
To be clear, the local learning coefficient, if you look at the definition, has a sensible interpretation in terms of what’s happening to the loss as you perturb certain weights, and you can tell a story about it, it doesn’t rely on the link between the Bayesian posterior and SGD training or something. To the degree that the empirical work succeeds, I think people will probably take this independent justification, so to speak, of the LLC as a quantity that is interesting, and think about it as a reflection of what’s happening to the internal structure of the model. Then, the mathematicians like myself will still be happy to go off and try and prove these things are justified, but I don’t see this as necessarily being a roadblock to using it quite extensively to study what’s happening during training.
Singular learning theory vs other deep learning theory
Filan:
Fair enough. I’d like to ask some questions thinking about SLT as compared to other potential theoretical approaches one could have to deep learning. The first comparison I have is to neural tangent kernel-style approaches. The neural tangent kernel, for listeners who don’t know, is basically this observation that, in the limit of infinitely wide neural networks under a certain method of initializing networks, there’s this observation that networks, during training, the parameters don’t vary very much and, because the parameters don’t vary very much, that means you can do this mathematical trick. It turns out that your learning is basically a type of kernel learning, which is essentially linear regression on a set of features. Luckily, it turns out to be an infinite set of features and you can do it…
I don’t know how I was going to finish that sentence, but it turns out to be feature learning on this set of features, and you can figure out what those features are supposed to be based on what your model looks like, what kinds of nonlinearities you’re using. There’s some family of theory trying to understand: what does the neural tangent kernel of various types of models look like, how close are we to the neural tangent kernel?
And if you believe in the neural tangent kernel story, you can talk about: the reason that neural networks generalize is that the neural tangent kernel, it tends to learn certain kinds of features before other kinds of features, and maybe those kinds of features are simpler. It seems plausible that you could do some story about phase transitions, and it’s a mathematically rigorous story. So I’m wondering, how do you think the single learning theory approach of understanding deep learning compares to the neural tangent kernel-style approach?
Murfet:
Yeah, good question. I think I’m not an expert enough on the NTK [neural tangent kernel] to give a very thorough comparison, but I’ll do my best. Let me say first the places in which I understand that the NTK says very deep and interesting things. It seems that this work on the mu parametrization seems very successful. At initialization, when this “taking the limit to infinite width” is quite justified because the weights really are independent, this seems like probably the principal success of deep learning theory, to the extent there are any successes: the study of that limit and how it allows you to choose hyperparameters for learning rates and other things. Again, I’m not an expert, but that’s my understanding of how it’s used, and that seems to be quite widely used in practice, as far as I know. So that’s been a great success of theory.
I don’t think I believe in statements outside of that initial phase of learning though. I think there, as far as I understand it, the claims to applicability of the NTK methods become hypotheses, unless you then perturb away from the Gaussian process limit. The deep parts of that literature seem to me to be accepting the position that in the infinite width limit, you get some Gaussian process that isn’t actually a good description of the training process away from initialization, but then you can perturb back in basically higher-order terms in the exponent of some distribution. You can put in higher-order terms and study systematically those terms to get back to finite width, attempt to perturb away from infinite width back to finite width and accommodate those contributions in some fashion. And you can do that with tools from random matrix theory and Gaussian processes.
And that looks a lot like what people do in Euclidean quantum field theory, and so people have been applying techniques from that world to do that. And I think they can say non-trivial things, but I think it is overselling it to say that that is a theory on the same level of mathematical rigor and depth as SLT. So I don’t think it says things about the Bayesian posterior and its asymptotics, in the way that SLT does, I think it’s aiming at rather different statements. And I think, at least in my judgment at the moment, it has a little bit of the flavor of saying qualitative things rather than quantitative things. Again, this is my outsider’s impression, and I could be wrong about what the state of things is there.
But I would say that one part of that story that I have looked at a little bit is the work that my colleague, Liam Hodgkinson has done here. They have some very interesting recent work on information criterion in over-parameterized models - I think the title is something like that. [It’s] partly inspired by Watanabe’s work, I think, looking at trying to take, not only NTK, but this general sort of approach, point of view to doing things like what the free energy formula in SLT does. And so I think that’s quite interesting. I have my differences of opinion with Liam about some aspects of that, but mathematics isn’t actually divided into camps that disagree with one another or something, right?
So if things are both true, then they meet somewhere. And I can easily imagine that… SLT is sort of made up of two pieces, one of which is using resolution of singularities to do Laplace integrals, oscillatory integrals, and the other is dealing with empirical processes that intervene in that when you try to put it in the context of statistics. And I don’t think these kinds of oscillatory integrals, these techniques, have been used systematically by the people doing NTK-like stuff or Euclidean field theory-like stuff, but I think that if you took those techniques and used them in the context of the random matrix theory that’s going on there, you’d probably find that the perturbations that they’re trying to do can be linked up with SLT somewhere. So I mean, I think it all probably fits together eventually, but right now they’re quite separated.
Filan:
Fair enough. So a related question I have is: one observation I have, from the little I know about the deep learning theory literature, is the variance of the distribution of how parameters are initialized matters. So one example of this is in deep linear models. If your initialization distribution of parameters has high enough variance, then it looks something like the NTK: you only have a small distance until the optimum. Whereas if all the parameters are really, really close to zero at initialization, you have this jumping between saddle points. And in deep networks at one initialization, you have this neural tangent kernel story, which crucially doesn’t really involve learning features; it has a fixed set of features and you need decide which ones to use. If you differ the variance of the initialization, then you start doing feature learning, and that seems qualitatively different.
If I think about how I would translate that to a singular learning theory story… At least in general, when people talk about Bayesian stories of gradient descent, often people think of the prior as being the initialization distribution. And in the free energy formula of singular learning theory, the place where the loss comes up and then the learning coefficient comes up, the prior comes in at this order one term that matters not very much, basically.
Murfet:
Well, late in training… I mean, late in the process it doesn’t matter.
Filan:
Yeah. So I guess my question is: is singular learning theory going to have something to say about these initialization distribution effects?
Murfet:
I haven’t thought about it at all, so this is really answering this question tabula rasa. I would say that from the asymptotic point of view, I guess we tend not to care about the prior, so this isn’t a question that we tend to think about too much so far, so that’s why I haven’t thought about it. But if you look at our model in the toy model of superposition, where you can really at least try and estimate order N term in the asymptotic, the log N term in the asymptotic, and then these lower order terms… And maybe I should say what this asymptotic is. If you take the Bayesian posterior probability that’s assigned to a region of parameter space and negative its logarithm (that’s an increasing function, so you could basically think about it as telling you how probable a given region is according to the posterior), you can give an asymptotic expansion for that in terms of N.
So for a large N, it looks like N times some number, which is kind of the average loss in that region or something like that, plus the local learning coefficient times log N plus lower order terms. The lower order terms we don’t understand very well, but there’s definitely a constant order term contributed from the integral of the prior over that region. Now if you look at the toy model of superposition, that constant order term is not insignificant at the scale of N at which we’re running our experiments. So it does have an influence, and I could easily imagine that this accounts for the kind of phenomena you’re talking about in DLNs [deep linear networks]. So a mathematician friend of mine, Simon Lehalleur, who’s an algebraic geometer who’s become SLT-pilled, maybe, has been looking at a lot of geometric questions in SLT and was asking me about this at some point.
And I guess I would speculate that if you just incorporated a constant term from those differences in initialization, that would account for this kind of effect. Maybe later in the year, we’ll write a paper about DLNs. At the moment, we don’t have complete understanding of the local learning coefficients away from the global minimum, the local learning coefficients of the level sets. I think we probably are close to understanding them, but there’s a bit of an obstacle to completely answering that question at the moment. But I think principle, that would be incorporated via the constant order term.
Which would, to be clear, not change the behavior at the very large N, but for some significant range of Ns, potentially including the ones you’re typically looking at in experiments, that constant order term could bias some regions against others in a way that explains the differences.
Filan:
Yeah. And I guess there’s also a thing where the constant order term, in this case the expansion is: you’ve got this term times N, you’ve got this term times the logarithm of N, you’ve got this term times the logarithm of the logarithm of N, if I remember correctly?
Murfet:
Yep.
Filan:
And then you have these constant things. And the logarithm of the logarithm of N is very small, right, so it seems like kind of easy for the constant order term to be more important than that, and potentially as important as the logarithm of N?
Murfet:
Yeah, although that log log N term is very tricky. So the multiplicity, Aoyagi’s proof… as I said, she understands deep linear networks, and in particular understands the multiplicity of the coefficient of this log log N term up to a -1. And this can get… if I remember correctly, as a function of the depth it has this kind of behavior and it becomes larger and larger [he mimes gradually increasing, ‘bouncing’ curves].
Filan:
Like a bouncing behavior with larger bounces?
Murfet:
Yeah, that’s right.
Filan:
Interesting.
Murfet:
Yeah, so that’s very wild and interesting. One of the things Simon is interested in is trying to understand [it] geometrically. Obviously Aoyagi’s proof is a geometric derivation of that quantity, but from a different perspective. Maybe Aoyagi has a very clear conceptual understanding of what this bouncing is about, but I don’t. So anyway, the log log N term remains a bit mysterious, but if you’re not varying the depth and you have a fixed depth, maybe it is indeed the case that the constant order terms could be playing a significant role.
Filan:
Sure. Right. So I guess a final question I have before I get into the relationship between singular learning theory and existential risk from AI: I’m more familiar with work done applying singular learning theory to deep learning. Is there much work outside that, of the singular learning theory of all the things people do outside my department?
Murfet:
Yes. I mean, that’s where the theory has been concentrated, I would say, so. I don’t want to give the impression that Watanabe didn’t think about neural networks; indeed, the class of models based on neural networks was one of the original motivations for him developing SLT. And he’s been talking about neural networks from the beginning, so early that the state of the art neural networks had tanh nonlinearities, so that’s how long Watanabe’s been talking about neural networks. Watanabe has been 20 years ahead of his time or something. But having said that, deeper neural networks with nonlinearities remain something that we don’t have a lot of theoretical knowledge about. There are some recent results giving upper bounds for various quantities, but in general, we don’t understand deeper neural networks in SLT.
The predominant theoretical work has been done for singular models that are not neural networks, various kinds of matrix factorization. There’s some interesting work by [Piotr] Zwiernik and collaborators looking at various kinds of graphical models, trees, deriving learning coefficients for probabilistic graphical models that have certain kinds of graphs. There’s papers on latent Dirichlet allocation, if that’s the correct expansion of the acronym LDA: many, many papers, dozens, I think. I wouldn’t be able to list all the relevant models here, but there’s quite a rich literature out there over the last several decades looking at other kinds of models.
How singular learning theory hit AI alignment
Filan:
All right. So at this stage I’d like to move on to: my experience of singular learning theory is, I’m in this AI existential risk space. For a while, people are chugging along doing their own thing. Then at one Effective Altruism Global, I have this meeting with this guy called Jesse Hoogland who says, “Oh, I’m interested in this weird math theory.” And I tell him, “Oh yeah, that’s nice. Follow your dreams.” And then it seems like at some point in 2023, it’s all everyone’s talking about, singular learning theory, it’s the key to everything, we’re all going to do singular learning theory now, it’s going to be amazing. How did that happen? What’s the story whereby someone doing singular learning theory gets interested in AI alignment or the reverse?
Murfet:
Yeah, I guess I can’t speak to the reverse so much, although I can try and channel Alexander [Gietelink Oldenziel] and Jesse [Hoogland] and Stan [van Wingerden] a little bit. I guess I can give a brief runthrough of my story. I cared about SLT before I cared about alignment, so maybe I’ll say briefly why I came to care about SLT. I’m an algebraic geometer by training, so I spent decades thinking about derived categories in algebraic geometry and some mathematical physics of string theory and its intersection with algebraic geometry, et cetera. And then I spent a number of years thinking about linear logic, which might seem unrelated to that, but has some geometric connections as well. And then because of some influence of friends and colleagues at UCLA where I was a postdoc, I paid attention to deep learning when it was taking off again in 2012, 2013, 2014. I’d always been a programmer and interested in computer science in various ways and sort of thought that was cool.
And then I saw AlphaGo happen, and then the original scaling laws paper from Hestness et al.. And it’s when I saw those two, AlphaGo and the Hestness et al. paper, that I was like, “huh, well maybe this isn’t just some interesting engineering thing, but maybe there’s actually some deep scientific content here that I might think about seriously, rather than just spectating on an interesting development somewhere else in the intellectual world.” So I cast around for ways of trying to get my hands on, with the mathematical tools that I had, what was going on in deep learning.
And that’s when I opened up Watanabe’s book, “Algebraic Geometry and Statistical Learning Theory”, which seemed designed to nerd-snipe me, because it was telling me geometry is useful for doing statistics. And then when I first opened it, I thought, that can’t possibly be true, this is some kind of crazy theory. And then I closed the book and put it away and looked at other things, and then came back to it eventually. So that’s my story of getting into SLT, from the point of view of wanting to understand universal mathematical phenomena in large-scale learning machines, and that’s my primary intellectual interest in the story. So I’ve been chugging away at that a little bit.
When I first started looking at SLT, it was - apart from Shaowei Lin, who did his PhD in SLT in the states, I believe, with Bernd Sturmfelds - mostly, it’s Watanabe, his students, and a few collaborators, mostly in Japan, a few people elsewhere, a very small community. So I was sitting here in Melbourne, chugging away reading this book and I had a few students, and then Alexander Oldenziel found me and asked me what this could say about alignment, if anything. And at the time, I found it very difficult to see that there was anything SLT could say about alignment, I guess, because as a mathematician, the parts of the alignment literature that I immediately found comprehensible were things like Vanessa Kosoy’s work or Scott Garrabrant’s work. These made sense to me, but they seemed quite far from statistical learning theory, at least the parts that I understood.
And so I think my answer originally to Alexander was, “no, I don’t think it is useful for alignment”, but reading more about the alignment problem and being already very familiar with capabilities progress, and believing that there was something deep and universal going on that that capabilities progress was sort of latching onto, but it not being some contingent phenomena on having a sequence of very complex engineering ideas, but more like “throw simple scaling and other things at this problem and things will continue to improve”. So that combination of believing in the capabilities progress and more deeply understanding what I was reading in the alignment literature about the problem… the product of that was me taking this problem seriously enough to think that maybe my initial answer, I could profit from thinking a little bit more extensively about it.
So I did that and outlined some of the ideas I had about how this kind of stage-wise learning, or phases and phase transitions that the Bayesian learning process and SLT talks about, how that might be by analogy with developmental biology used to understand how structure develops in neural networks. So I had some preliminary ideas around that [in the] middle of 2023, and those ideas were developed further by Alexander [Oldenziel] and Jesse Hoogland and Stan van Wingerden and various of my students and others, and that’s where this developmental interpretability agenda came from. And I think that’s sort of around the time you ran into SLT, if I remember correctly.
Filan:
Yeah. The time I ran into it is: so, I hear a few different people mention it, including, if people listen to the episode of this podcast with Quintin Pope, he brings it up and it sounds interesting. And some other people bring it up, that sounds interesting. And then I hear that you guys are running some sort of summer school thing, a week where you can listen to lectures on single learning theory. And I’m like, “oh, I could take a week off to listen to some lectures, it seems kind of interesting”. This is summer of 2023. Theselectures are still up on YouTube, so you can hear some guy ask kind of basic questions - that’s me.
Murfet:
Yeah. I guess it took me a while to appreciate some of the things that… I mean, I guess John Wentworth has also been posting in various places how he sees SLT relating to some of the aspects of the alignment problem that he cares about. Now I see more clearly why some of the very core problems in alignment, things like sharp left turns and so on, the way that people conceptualize them… how SLT, when you first hear about it, might map onto that in a way that makes you think it could potentially be interesting.
I think my initial take being negative was mostly to do with it just being such a big gap at that time, the middle of last year, between SLT being a very highly theoretical topic…. I mean, I should be clear. The WBIC, which is the widely applicable Bayesian information criterion, which is a piece of mathematics and statistics that Watanabe developed, has been very widely used in places where the BIC [is used]. This is not an esoteric, weird mathematical object. This is a tool that statisticians use in the real world, as they say. The WBIC has been used in that way as well. And so the work we’ve been doing, with the local learning coefficient and SGLD and so on, is by far not the only place where SLT has met applications. That’s not the case. I don’t want to give that impression.
But the way SLT felt to me at that time was: there’s just so many questions about whether the Bayesian learning process is related to SGD training and all these other things we were discussing. So I think it was quite a speculative proposal to study the development process using these techniques, middle of last year. I think we’ve been hard at work over the last year seeing if a lot of those things pan out, and they seem to. So I think it’s much less speculative now to imagine that SLT says useful things, at least about stage-wise development in neural networks. I think it says more than that about questions of generalization that are alignment-relevant, but I think it was appropriate a year ago to think that there was some road to walk before it was clear that this piece of mathematics was not a nerd-snipe.
Filan:
Sure. So at some point, this guy, Alex Oldenziel, reaches out to you and says, “hey, how is single learning theory relevant to alignment?” And instead of deleting that email, you spent some time thinking about it. Why?
Murfet:
Well, I should insert a little anecdote here, which is I think I did ignore his first email, not because I read it and thought he was a lunatic, but just because I don’t always get to every email that’s sent to me. He persisted, to his credit.
Filan:
Why did it feel interesting to you, or why did you end up pursuing the alignment angle?
Murfet:
I had read some of this literature before in a sort of “curious but it’s not my department” kind of way. I quite extensively read Norbert Wiener’s work. I’m a big fan of Wiener, and he’s written extensively, in God & Golem and The Human Use of Human Beings and elsewhere, precisely about the control problem or alignment problem in much the same way as modern authors do. And so I guess I had thought about that and seen that as a pretty serious problem, but not pressing, because AI didn’t work. And then I suppose I came to believe that AI was going to work, in some sense, and held these two beliefs, but in different parts of my brain. And it was Alexander that sort of caused the cognitive dissonance, the resolution of which was me actually thinking more about this problem.
So that’s one aspect of it - just causing me to try and make my beliefs about things coherent. But I think that wouldn’t have been sufficient without a second ingredient, and the second ingredient was: to the degree you assign a probability to something like AGI happening in a relatively short period of time, it has to affect your motivational system for doing long-term fundamental work like mathematics.
So as a kind of personal comment, the reason I do mathematics is not based on some competitive spirit or trying to solve tricky problems or something like that. I am very much motivated as a mathematician by the image of some kind of collective effort of the human species to understand the world. And I’m not [Ed] Witten or [Maxim] Kontsevich or [Alexander] Grothendieck or somebody, but I’ll put my little brick in the wall. And if I don’t do it, then maybe it’ll be decades before somebody does this particular thing. So I’m moving that moment forward in time, and I feel like that’s a valid use of my energies and efforts, and I’ll teach other people and train students to do that kind of thing, and I felt that was a very worthwhile endeavor to spend my life professionally on.
But if you believe that there are going to be systems around in 10 years, 20 years, 30 years - it doesn’t really matter, right, because mathematics is such a long-term endeavor. If you believe that at some time, soon-ish, systems will be around that will do all that for $.05 of electricity and in 20 seconds… If that is your motivation for doing mathematics, it has to change your sense of how worthwhile that is, because it involves many tradeoffs against other things you could do and other things you find important.
So I actually found it quite difficult to continue doing the work I was doing, the more I thought about this and the more I believed in things like scaling laws and the fact that these systems do seem to understand what they’re doing, and there’s interesting internal structures and something going on we don’t understand. So I’d already begun shifting to studying the universal phenomena involved in learning machines from a geometric perspective, and I picked up statistics and empirical processes and all that. I’d already started to find that more motivating than the kind of mathematics I was doing before. And so it wasn’t such a big jump from that to being motivated by alignment and seeing a pathway to making use of that comparative advantage in theory and mathematics and seeing how that might be applicable to make a contribution to that problem.
There’s many details and many personal conversations with people that helped me to get to that point, and in particular, my former master’s student, Matt Farrugia-Roberts, who was in my orbit probably the person who cared about alignment the most, who I talked to the most about it. So that’s what led me to where I am now. Most of my research work is now motivated by applications to alignment.
Payoffs of singular learning theory for AI alignment
Filan:
Sure. My next question is: concretely, what do you think it would look like for singular learning theory to be useful in the project of analyzing or preventing existential risk from AI?
Murfet:
The pathway to doing that that we’re currently working on is providing some sort of rigorously founded empirical tools for understanding how structure gets into neural networks. And that has similar payoffs as many things [in] interpretability might, and also potentially some of the same drawbacks. So I can talk about that in more detail, but maybe it’s better to sketch out, at a very high level, the class of things that theories like SLT might say and which seem related to the core problems in alignment. Then we can talk about some detailed potential applications.
So I rather like the framing that Nate Soares gave in a blog post he wrote in 2022, I think. I don’t know if that’s the post that introduced the term “sharp left turn”, but it’s where I learned about it.
So let me give a framing of what Soares calls the core technical problem in alignment, and which I tend to agree seems like the core problem. I’ll say it in a way which I think captures what he’s saying but is my own language. If we look at the way that large-scale neural networks are developing, they become more and more competent with scale both in parameters and data, and it seems like there’s something kind of universal about that process. What exactly that is, we don’t quite know, but many models seem to learn quite similar representations, and there are consistencies across scale and across different runs of the training process that seem hard to explain if there isn’t something universal.
So then, what is in common between all these different training processes? Well, it’s the data. So I guess many people are coming to a belief that structure in the data, whatever that means, is quite strongly determinant of the structures that end up in trained networks, whatever you take that to mean, circuits or whatever you like.
So then from that point of view, what Soares says is… his terms are “capabilities generalize further than alignment”. And the way I would put that is: if your approach to alignment is engineering the data distribution - things like RLHF or safety fine-tuning and so on, [that] fundamentally look like training with modified data that tries to get the network to do the thing you want it to do; if we just take as a broad class of approaches “engineer the data distribution to try and arrange the resulting network to have properties you like” -
If that’s your approach, then you have to be rather concerned with which patterns in the data get written more deeply into the model, because if… And Soares’s example is arithmetic: if you look in the world, there are many patterns that are explained by arithmetic. I don’t think this is how current models learn arithmetic, but you could imagine future multimodal models just looking at many scenes in the world and learning to count and then learning rules of arithmetic, et cetera, et cetera.
So anyway, there are some patterns in the world that are very deep and fundamental and explain many different samples that you might see. And if this is a universal phenomenon, as I believe it is, that the data determines structure in the models, then patterns that are represented more deeply in the world will tend perhaps to get inscribed more deeply into the models. Now, that’s a theoretical question. So that’s one of the questions you might study from a theoretical lens. Is that actually the case?
But the story with DLNs [deep linear networks] and learning modes of the data distribution in order of their singular values and all that tends to suggest that this is on the right track. And I think SLT has something more general to say about that. I can come back to that later, but I buy this general perspective that in the data, there are patterns. Not all patterns are equal, some are more frequent than others, some are sort of deeper than others in the sense that they explain more. And capabilities - whatever that means, but reasoning and planning and the things that instrumental convergence wants to talk about models converging to - these kinds of things might be patterns that are very deeply represented.
Whereas the things you are inserting into the data distribution to get the models to do what you want, the kind of things that you’re doing with RLHF for example, might not be as primary as those other patterns, and therefore the way they get written into the model in the end might be more fragile. And then when there’s a large shift in the data distribution, say from training to deployment or however you want to think about that, how do you know which of those structures in your model, associated to which structures in the data distribution, are going to break and which ones will not? Which ones are sacrificed by the model in order to retain performance?
Well, maybe it’s the ones that are shallower rather than the ones that are deeper. And on that theory, capabilities generalize further than alignment. So I think that post is sometimes criticized by its emphasis on the evolutionary perspective, on the contrast between in-lifetime human behavior and what evolution is trying to get people to do and so on. But I think that’s missing the point to some degree. I think this general perspective of structure in the data determining structure in the models, not all structure being equal, and our alignment attempts, if they go through structuring the data, perhaps being out-competed by structures in the data that are deeper when it comes to what happens when data distributions shift - I think this is a very sensible, very grounded, quite deep perspective on this problem, which as a mathematician makes a lot of sense to me.
So I think this is a very clear identification of a fundamental problem in Bayesian statistics even absent a concern about alignment, but it does seem to me to be quite a serious problem if you’re attempting to do alignment by engineering the data distribution. So I think my mainline interest is in approaching that problem and, well, we can talk about how you might do that. Obviously it’s a difficult and deep problem empirically and theoretically, and so we’re sort of building up to that in various ways, but I think that is the core problem that needs to be solved.
Filan:
Sure. I guess if you put it like that, it’s not obvious to me what it would look like for singular learning theory to address this, right? Maybe it suggests something about understanding patterns in data and which ones are more fundamental or not, but I don’t know, that’s a very rough guess.
Murfet:
I can lay out a story of how that might look. Obviously, this is a motivating story, but not one that has a lot of support right now. I can say the ingredients that lead into me thinking that that story has some content to it.
So we’ve been studying for the last year how the training process looks in models of various sizes and what SLT says about that, and part of the reason for doing that is because we think… I mean, other people have independent reasons for thinking this, but from an SLT perspective, we think that the structure of the training process or learning process reflects the structure of the data, what things are in it, what’s important, what’s not. So if it’s correct that the structure of the data is somehow revealed in the structure of the learning process, and that also informs the internal structures in the model that emerge and then affect later structure and then are present in the final model.
So that starts to give you some insight into, [first], how - the mechanism by which structures in the data become structures in the model. If you don’t have that link, you can’t really do much. So if you can understand how structure in the data becomes structures - say, circuits or whatever - in the final model, that’s already something.
Then if you also understand the relative hierarchy of importance, how would you measure that? There’s several things you’d want to do in order to get at this question. You’d want to be able to, first of all, know what the structure in the data is. Well, unfortunately, training networks is probably the best way to find out what the structure in the data is. But suppose you’ve trained a network which sort of is a reflection, holding a mirror up to the data, and you get a bunch of structure in that model, well, then you’re just looking at a big list of circuits. How do you tell which kinds of structure are associated to deep things in the data, which are very robust and will survive under large scale perturbations, and [which are] very fragile structures that are somewhat less likely to survive perturbations in the data distribution if you had to keep training or expose the network to further learning.
Well, those are questions. Then there’s a question of stability of structure and how that relates to things you can measure, but these are fundamentally geometric questions from our point of view. So I think it actually is in scope for SLT to… Not right now, but there are directions of development of the theory of SLT that augment the invariants like the local learning coefficient and the singular fluctuation with other invariants you could attempt to estimate from data, which you could associate to these structures as you watch them emerging and which measures, for example, how robust they are to certain kinds of perturbations in the data distribution, so that you get some idea of not only what structure is in the model, but what is deep and what is shallow.
And how that pays off for alignment exactly, I guess it’s hard to say right now, but this seems like the kind of understanding you would need to have if you were to deal with this problem of generalization of capabilities outpacing alignment. If you were to have empirical and theoretical tools for talking about this sensibly, you’d at least have to do those things, it seems to me. So that’s how I would see concretely…
I mean, we have ideas for how to do all those things, but it’s still very early. The part that we sort of understand better is the correspondence between structure in the data and development, and the stages, and how those stages do have some geometric content. That’s what the changes in the local learning coefficient says. So all of that points in some direction that makes me think that the story I was just telling has some content to it, but that is the optimistic story of how SLT might be applied to solve eventually, or be part of the solution to [the alignment] problem, that we’re working towards.
Filan:
Sure. So I guess if I think about what this looks like concretely, one version of it is this developmental interpretability-style approach of understanding: are there phase transitions in models? At what points do models really start learning a thing versus a different thing? And then I also see some work trying to think about what I would think of as inductive biases. So in particular, there’s this LessWrong post. Is that too undignified? I don’t know if you posted it elsewhere, but there’s this thing you posted about-
Murfet:
Not undignified. Yes, it was a LessWrong post.
Filan:
Something about, you call it “short versus simple”. Thinking about a singular learning theory perspective on learning codes of Turing machines that are generating data and saying something beyond just the number of symbols in the code. Perhaps you want to explain that a little bit more for the audience?
Murfet:
Sure. There’s been an interesting thread within the alignment literature, I think, if I’m correct, going back to Christiano writing about ghosts in the Solomonoff prior or something. And then Evan Hubinger wrote quiteabit about this, and others, which is motivated by the observation that if you’re producing very capable systems by a dynamical process of training, and you want to prove things about the resulting process - or maybe that’s too ambitious, but at least understand something about the resulting process and its endpoint - then you might like to know what kind of things that process typically produces, which is what “inductive biases” means.
And neural networks are not Turing machines, but we have some understanding of certain kinds of distributions over Turing machine codes. And there’s a kind of Occam’s razor principle there, which is spiritually related to the free energy formula that we were discussing earlier, although not directly analogous without making some additional choices.
But anyway, the story about inductive biases and its role in alignment has been going on for a number of years, and there’s been, I think, quite reasonably some discussion that’s critical of that in recent months on LessWrong. And my post sort of came out of reading that a little bit. So let me maybe just characterize briefly what the discussion is for some context.
We don’t understand the inductive bias of SGD training. We know some bits and pieces, but we really don’t understand systematically what that bias is. We do not understand that it’s a bias towards low Kolmogorov complexity functions. There are somepaperspointing in that direction. I don’t think they conclusively establish that. So I think we are just quite in the dark about what the inductive biases of SGD training are.
And I read these posts from, say, Christiano and Hubinger as saying, “Well, here we know about the inductive biases in some nearby conceptually similar thing. And if that knowledge could be used to reason about SGD training, then here would be the consequences. And these look potentially concerning from an alignment perspective.” And my model of both Christiano and Hubinger is that I think neither of them would claim those are ironclad arguments because there’s a big leap there, but it seems sufficient to motivate further research empirically, which is what, for example, Hubinger has been doing with the Sleeper Agents work.
So I think that’s very interesting, and I buy that, but with the big caveat that there is this gap there, that it isn’t on solid theoretical ground. And then you can criticize that work and say that it’s kind of spinning stories about how scary inductive biases are. And there were some posts from Nora Belrose and Quintin Pope critiquing the [argument, saying] if you take uncritically this story about inductive biases without really internalizing the fact that there is this big gap in there, then you might make overconfident claims about what the consequences of inductive biases may be.
So in some sense, I think both sides are correct. I think it’s reasonable to look at this and think, “Ah, this might tell us something, and so I’ll go away and do empirical work to see if that’s true.” I think it’s also accurate to think that people may have become a little bit overly spooked by our current understanding of inductive biases. So in that context, what I wanted to do with this post was to point out that as far as our current state-of-the-art knowledge about Bayesian statistics goes, which is SLT, at least if by “inductive bias” he means “which parameters does the Bayesian posterior prefer?”…
This is not description length. It’s not even like description length, it’s just something else. And we don’t know what that is yet. But this step that Christiano and Hubinger were making from thinking about description length and inductive biases in SGD training as maybe being related, I’m pointing to a particular piece of that gap where I see that this is not justified.
Now, I think that maybe the concern that they derive from that connection may still be justified, but I think thinking about it roughly as description length is simply wrong. And then I gave a particular example in that post - not in neural networks, but in a Turing machine-oriented setting - of how the local learning coefficient, which in some cases, like this simple situation we were describing at the beginning of this podcast, where you have energy levels and then there’s sums of squares, and the local learning coefficient is just the number of squares, which is sort of the co-dimension. So that’s somewhat like description length.
So if you have a system where the LLC, the local learning coefficient, is basically half the number of variables you need to specify your thing, then that is description length, because you take your universal Turing machine, it’s got a code tape, and you need n squares to specify your code. Well, that’s roughly speaking n variables whose value you need to specify, and you need that value to stay close to the value you specified and not wander off in order to execute the correct program.
So there is quite a legitimate rigorous connection between description length and the local learning coefficient in the case where you’re dealing with models that have this near-regularity behavior that the loss function is just locally sums of squares. But it’s typical, as soon as you perturb this kind of universal Turing machine perspective and introduce some stochasticity, that the local learning coefficient becomes immediately more exotic and includes, for example, a bias towards error correction, which I’d present in the following way.
If you give someone some instructions, it’s no good those instructions being short if they’re so fragile that they can’t execute them reliably. So there’s actually some advantage to trading off succinctness against robustness to errors in execution, where you don’t have to get everything perfect and you’ll still more or less get what you want. And there’s some precise mathematical statement of that in that post.
That’s in the setting of Turing machines, so it’s provably the case that there will be some preference for Turing machines, which are insensitive to certain kinds of errors if they’re executed in some slightly exotic way… The setting really is not meant to be thought of as directly analogous to what’s happening in neural networks. But I think there’s a high level of conceptual insight, which I sort of noticed after… I thought of those ideas along with my student, Will Troiani, at a meeting we had in Wytham that was organized by Alexander [Oldenziel] and Stan [van Wingerden] and Jesse [Hoogland].
There were some linear logic people there, and I was talking with them about this, and I had this idea with Will about error correction. And then later I twigged that there is a phenomenon in neural networks, these backup heads, where it does seem that neural networks may actually have a bias towards reliably computing important things by making sure that if some weight is perturbed in such a way that it takes out a certain head, that another head will compensate. So I’m speculating now, but when I see that sort of phenomenon, that makes sense to me, as a general principle of Bayesian statistics, that short is not necessarily better, degenerate is better, and degenerate can be both short but also redundant.
Filan:
Right. So I guess to me this points to a qualitatively different way that singular learning theory could be useful, where one way is understanding developmental stages and how structure gets learned over time with data, and there’s this other approach which is better understanding what kinds of solutions Bayesian inference is going to prefer in these sorts of messy systems. And maybe that helps inform arguments that people tend to have about what sorts of nasty solutions should we expect to get. Does that seem fair to you?
Murfet:
Yeah, I think so. I guess this observation about the inductive biases has sort of been on the side or something because we’ve been busy with other things. One of the things that my former student, Matt Farrugia-Roberts, who I mentioned earlier, and potentially others - I don’t know if Garrett Baker is interested in this, but he and Matt are working on an RL project right now that maybe eventually develops in this direction…
You could imagine that in a system that is doing reinforcement learning, that potentially some of these inductive biases - if they exist in neural networks, and that’s still speculation, but if this observation I’m making about this other setting with Turing machines, if this inductive bias towards error correction or robustness is universal, then you could imagine that this is actually a pretty significant factor in things like RL agents choosing certain kinds of solutions over others because they’re generally more robust to perturbations in their weights - things like making your environment safe for you to make mistakes. That’s speculation, but I do think that I agree that this is an independent direction in which potentially you can derive high-level principles from some of these mathematical ideas that would be useful.
Does singular learning theory advance AI capabilities?
Filan:
Fair enough. So another question I have about this interplay between singular learning theory and AI alignment, AI existential risk is: a lot of people in the field use this kind of simplified model where there are some people working on making AI more generally capable and therefore more able to cause doom. And there are other people who are working on making sure AI doesn’t cause doom. And when you’re evaluating some piece of research, you’ve got to ask, to what extent does it advance capabilities versus alignment? And if it advances capabilities much more than alignment, then maybe you think it’s bad or you’re not very excited about it.
So with singular learning theory, one might make the critique that, well, if we have this better theory of deep learning, it seems like this is just going to generally be useful, and maybe it’s about as useful for causing doom as for preventing doom, or maybe it’s more useful for causing doom than for preventing doom, and therefore people on the anti-doom side should just steer clear of it. I’m wondering what you think about that kind of argument.
Murfet:
Yeah, it’s a good question. I think it’s a very difficult question to think about properly. I have talked with many people about it. Not only on my own, but along with Alexander and Jesse and Stan and the other folks at Timaeus I’ve talked about this quite a bit. I talked with Lucius Bushnaq about it and some of the junior MIRI folks. So I’ve attempted to think about this pretty carefully, but I still remain very uncertain as to how to compute on these trade-offs, partly because especially this kind of research…
I mean, [in] empirical research, I suppose, you partly get out about as much as you put in or something. You have a certain number of experiments, you get a certain number of bits of insight. But theory sometimes doesn’t work like that. You crack something, and then lots and lots of things become visible. There’s a non-linear relationship between the piece of theory and the number of experiments it kind of explains. So my answer to this question could look extremely foolish just six months from now if a certain direction opens up, and then just very clearly the trade-off is not what I thought it was.
I guess one response to this question would be that we have prioritized thinking about directions within the theory that we think have a good trade-off in this direction. And for the things we’re currently thinking about, I just don’t see how the ratio of contribution to alignment to contribution to capabilities is too small to justify doing it. So we are thinking about it and taking it seriously, but I don’t actually have a very systematic way of dealing with this question, I would say, even at this point. But I think that applies to many things you might do on a technical front.
So I guess my model is something like… And here I think Alexander and I differ a little, so maybe I’ll introduce Alexander’s position just to provide context. So I think if you have a position that capabilities progress will get stuck somewhere - for example, perhaps it will get stuck… I mean, maybe the main way in which people imagine it might get stuck is that there’s some fundamental gap between the kind of reasoning that can be easily represented in current models and the kind of reasoning that we do, and that you need some genuine insight into something involved - architecture or training processes or data, whatever - to get you all the way to AGI. And there’s some threshold there, and that’s between us and the doom. If there is such a threshold, then conceivably, you get unstuck by having better theory of how universal learning machines work and the relationship between data and structure, and then you can reverse engineer that to design better architectures. So I guess that’s pretty obviously the mainline way in which SLT could have a negative impact. If, on the other hand, you think that basically not too much more is required, nothing deep, then it’s sort of like, capabilities are going to get there anyway, and the marginal negative contribution from doing more theoretical research seems not that important.
So I think that seems to me the major divide. I think in the latter world where you sort of see systems more or less getting to dangerous levels of capability without much deeper insight, then I think that SLT research, I’m not that concerned about it. I think just broadly, one should still be careful and maybe not prioritize certain avenues of investigation that seem disproportionately potentially likely to contribute to capabilities. But on the whole, I think it doesn’t feel that risky to me. In the former case where there really is going to be a threshold that needs to be cracked with more theoretical progress, then it’s more mixed.
I guess I would like to err on the side of… Well, my model is something like it would be extremely embarrassing to get to the point of facing doom and then be handed the solution sheet, which showed that actually it wasn’t that difficult to avert. You just needed some reasonably small number of people to think hard about something for a few years. That seems pretty pathetic and we don’t know that we’re not in that situation. I mean, as Soares was saying in this post, he also, at least at that time, thought it wasn’t like alignment was impossible, but rather just a very difficult problem you need a lot of people thinking hard about for some period of time to solve, and it seems to me we should try. And absent a very strong argument for why it’s really dangerous to try, I think we should go ahead and try. But I think if we do hit a plateau and it does seem like theoretical progress is likely to critically contribute to unlocking that, I think we would have to reevaluate that trade-off.
Filan:
Yeah. I wonder: it seems like you care both about whether there’s some sort of theoretical blocker on the capabilities side and also whether there’s some theoretical blocker on the alignment side, right?
Murfet:
Yeah.
Filan:
If there’s one on the alignment side but not on the capabilities side, then you’re really interested in theory. If there’s one on the capability side but not on the alignment side, then you want to erase knowledge of linear algebra from the world or something. Not really. And then if there’s both or neither, then you’ve got to think harder about relative rates. I guess that would be my guess?
Murfet:
Yeah, I think that’s a nice way of putting it. I think the evidence so far is that the capabilities progress requires essentially no theory, whereas alignment progress seems to, so far, not have benefited tremendously from empirical work. I mean, I guess it’s fair to say that the big labs are pushing hard on that and believe in that, and I don’t know that they’re wrong about that. But my suspicion is that these are two different kinds of problems, and I do see this as actually a bit of a groupthink error in my view, in the more prosaic alignment strategy, which is: I think a lot of people in computer science and related fields think, maybe not consciously, but unconsciously feel like deep learning has succeeded because humans are clever and we’ve made the things work or something.
I think many clever people have been involved, but I don’t think it worked because people were clever. I think it worked because it was, in some sense, easy. I think that large scale learning machines want to work and if you just do some relatively sensible things… Not to undersell the contributions of all the people in deep learning, and I have a lot of respect for them, but compared to… I mean, I’ve worked in deep areas of mathematics and also in collaboration with physicists, the depth of the theory and understanding required to unlock certain advances in those fields, we’re not talking about that level of complexity and depth and difficulty when we’re talking about progress in deep learning.
Filan:
I don’t know, I have this impression that the view that machines just want to learn and you just have to figure out some way of getting gradients to flow. This seems similar to the Bitter Lesson essay. To me, this perspective is… I feel like I see it in computer scientists, in deep learning people.
Murfet:
Mm-hmm. Yeah. But I think that the confidence derived from having made that work seems like it may lead to a kind of underestimation of the difficulty of the alignment problem. If you think about, “Look, we really cracked deep learning as a capabilities problem and surely alignment is quite similar to that. And therefore because we’re very clever and have lots of resources and we really nailed this problem, therefore we will make a lot of progress on that problem.” That may be true, but it doesn’t seem like it’s an inference that you can make, to me. So I guess I do incline towards thinking that alignment is actually a different kind of problem, potentially, to making the thing work in the first place.
And this is quite similar to the view that I was attributing to Soares earlier, and I think there are good reasons, fundamental reasons from the view of statistics or whatever to think that that might be the case. I think it’s not just a guess. I do believe that they are different kinds of problems, and therefore that has a bearing on the relative importance of… I do think alignment may be theoretically blocked, because it is a kind of problem that you may need theoretical progress for. Now, what does that mean? If we look at the empirical approaches to alignment that are happening in the big labs, and they seem to really be making significant contributions to the core problems of alignment, and at the same time capabilities sort of seem blocked, then I guess that does necessarily mean that I would move against my view on the relative value of theoretical progress, because it might not be necessary for alignment, but might unblock capabilities progress or something.
Filan:
Yeah. For what it’s worth, I think, at least for many people, I get the impression that the “optimism about prosaic alignment” thing maybe comes more from this idea that somehow the key to alignment is in the data and we’ve just got to figure out a way to tap into it, rather than “we’re all very smart and we can solve hard problems, and alignment’s just as hard as making capabilities work.” This is my interpretation of what people like Nora Belrose, Quintin Pope, Matthew Barnett think. They’re welcome to correct me, I might be misrepresenting them. I guess there’s also a point of view of people like Yann LeCun who think that we’re not going to have things that are very agentic, so we don’t need to worry about it. Maybe that is kind of a different perspective.
Open problems in singular learning theory for AI alignment
Filan:
So changing topics a bit: suppose someone has listened to this podcast and they’re interested in this research program of developing singular learning theory, making it useful for AI alignment things: what are the open problems or the open research directions that they could potentially tap into?
Murfet:
I’ll name a few, but there is a list on the DevInterp webpage. If you go to DevInterp, there’s an “open problems” page and there’s a Discord there where this question gets asked fairly frequently and you’ll find some replies.
Maybe there are several different categories of things which are more or less suited to people with different kinds of backgrounds. I think there already are, and will be an increasing number of, people coming from pure mathematics or rather theoretical ends of physics who ask this question. To them, I have different answers to people coming from ML or computer science, so maybe I’ll start with the more concrete end and then move into the more abstract end.
So on the concrete front, the current central tool in developmental interpretability is local learning coefficient estimation. I mentioned that this work that Zach [Furman] and Edmond [Lau] did gives us some confidence in those estimates for deep linear networks. But there is a lot of expertise out there in approximate Bayesian sampling from people in probabilistic programming to just Bayesian statistics in general. And I think a lot more could be done to understand the question of why SGLD is working to the extent it works. There was a recent deep learning theory conference in Lorne, organized by my colleague, Susan [Wei] and Peter Bartlett at DeepMind, and I posed this as an open problem there. I think it’s a good problem. So the original paper that introduced SGLD has a kind of proof that it should be a good sampler, but this proof… Well, I wouldn’t say it’s actually a proof of what you informally mean when you say SGLD works. So I would say it’s actually a mystery why SGLD is accurately sampling the LLC, even in deep linear networks.
Understanding that would give us some clue as to how to improve it or understand what it’s doing more generally. And this kind of scalable approximate Bayesian sampling will be fundamental to many other things we’ll do in the future with SLT. So if we want to understand more about the learned structure in neural networks, how the local geometry relates to this structure of circuits, et cetera, et cetera, all of that will at the bottom rely on better and better understanding of these approximate sampling techniques. So I would say there’s a large class of important fundamental questions to do with that.
A second class of questions, more empirically, is studying stagewise development in more systems, taking the kind of toolkit that we’ve now developed and applied to deep linear networks, to the toy model of superposition and small transformers, just running that on different systems. We had some MATS scholars, Cindy Wu and Garrett Baker and Xinyu Qian looking at this recently, and there’s a lot more in that direction one can do. I think those are sort of the main [categories]. Beyond that, maybe I’ll defer to the list of open problems on the webpage and talk about some more intermediate questions.
So there’s a lot more people at the moment with ML backgrounds interested in developmental interpretability than there are with the kind of mathematical backgrounds that would be required to do more translation work. At the moment, there are various other things in SLT, like the singular fluctuation, which we haven’t been using extensively yet, but which we’re starting to use. And I know there’s a PhD student of [Pratik] Chaudhari who’s investigating it and maybe a few others. But this is the other principal invariant besides the learning coefficient in SLT, which should also tell us something interesting about development and structure, but which hasn’t been extensively used yet. So that’s another interesting direction. Of course you can just take quantities and go and empirically use them, but then there’s questions… using the local learning coefficient, there’s some subtleties, like the role of the inverse temperature and so on.
And there are theoretical answers to the question, like, “Is it okay for me to do X?” When you’re doing local learning coefficient estimation, are you allowed to use a different inverse temperature? Well, it turns out you are, but the reason for that has some theoretical basis and there is a lower set of people who can look at the theory and know that it’s justified to do X. So if you have a bit more of a mathematical background, helping to lay out more foundations, knowing which things are sensible to do with these quantities is important. Singular fluctuation is one.
Then ranging through to the more theoretical, at the moment, it’s basically Simon and myself and my PhD student, Zhongtian [Chen], who have a strong background in geometry and they were working on SLT, Simon Lehalleur, as I mentioned earlier. Currently, a big problem with SLT is that it makes use of the resolution of singularities to do a lot of these integrals, but that resolution of singularities procedure is kind of hardcore or something. It’s a little bit hard to extract intuition from. So we do have an alternative perspective on the core geometry going on there based on something called jet schemes, which has a much more dynamical flavor and Simon’s been working on that and Zhongtian as well a little bit.
So I would say we’re maybe a few months away from having a pretty good starting point from anybody who has a geometric background to see ways to contribute to it. So the jet scheme story should feed into some of this discussion around stability of structures to data distribution shift that I was mentioning earlier. There’s lots of interesting theoretical open problems there to do with deformation of singularities that should have a bearing on basic questions in data distribution change in Bayesian statistics. So that’s a sketch of some of the open directions. But relative to the number of things to be done, there are very few people working on this. So if you want to work on this, show up in the Discord or DM me or email me and ask this question, and then I will ask what your background is and I will provide a more detailed answer.
What is the singular fluctuation?
Filan:
Sure. At the risk of getting sucked down a bit of a rabbit hole, the singular fluctuation… I noticed that in this paper, Quantifying Degeneracy, it’s one of the two things you develop an estimator for. Maybe I should just read that paper more clearly, but I don’t understand what the point of this one is. The local learning coefficient, we’re supposed to care about it because it shows up in the free energy expansion and that’s all great. What is the singular fluctuation? Why should I care about it?
Murfet:
Okay, I’ll give two answers. The relation between them is in the mathematics and maybe not so clear. The first answer, which is I think the answer Watanabe would give, or rather the gray book would give, is that, if you look at the gap between… We were talking earlier about the theoretical generalization error, the KL divergence from the truth to the predictive distribution, which is some theoretical object, you’ll never know what that is. So you’re interested then in the gap between that and something you can actually estimate, which you can call the training error. It’s what Watanabe calls the training error. I think one should not conflate that with some other meaning of training error that you might have in mind. Anyway, it’s some form of generalization error, which can be estimated from samples. So if you can understand that gap, then obviously you can understand the theoretical object. And that gap is described by a theorem in terms of the learning coefficient and the singular fluctuation.
So the singular fluctuation controls the gap between these theoretical and empirical quantities, is one way of thinking about it. So that is its theoretical significance. It’s much less understood. Watanabe flags in a few different places that this is something he would be particularly interested in people studying. For example, we don’t know bounds on it in the way that we might know bounds on the local learning coefficient. You can estimate it from samples in a similar way. We don’t have any results saying that estimates based on SGLD are accurate or something because we don’t have… I mean, those depend on knowing theoretical values, which are much less known in general than learning coefficient values.
The second answer to what the singular fluctuation is, is that it tells you something about the correlation between losses for various data samples. So if you take a fixed parameter and you look at some data set, it’s got N things in it, N samples. Then you can look at the loss for each sample, whose average is the empirical loss.
So for the i-th sample, you can take Li, which is the loss of that parameter on that sample, but if you think about the parameter as being sampled from the Bayesian posterior locally, that’s a random variable that depends on W, the parameter. And then you can take the covariance matrix of those expectations with respect to all the different samples: EW of loss i times loss j, where the losses depend on the parameter, which is sampled from the posterior. And that covariance matrix is related to the singular fluctuation.
So it’s quite closely related to things like influence functions, or how sensitive the posterior is for including or leaving out certain samples, or leverage samples, or these kinds of notions from statistics. So it’s a kind of measure of how influential… Well, yeah, so it’s that covariance matrix. We think that this can be a tool for understanding more fine-grained structure than the local learning coefficient or correlation functions in that direction: not only correlation functions of two values like that, but more… So this is going in the direction of extracting more fine-grained information from the posterior than you’re getting with the local learning coefficient, at some conceptual level.
How geometry relates to information
Filan:
Sure. Gotcha. So before we basically wrap up, is there any question that you wish I’d asked during this interview, but that I have not yet asked?
Murfet:
Well, how about a question you did ask but I didn’t answer? We can circle back to: you asked me, I think, at some point, about how to think about the local learning coefficient for neural networks, and then I told some story about a simplified setting. So maybe I’ll just briefly come back to that. So if you think about, given an architecture and given data, the loss function represents constraints. It represents a constraint for certain parameters to represent certain relationships between inputs and outputs. And the more constraints you impose, somehow the closer you get to some particular kind of underlying constraint. So that’s what the population loss is telling you.
But if you think about, “Okay, so what are constraints?”: constraints are equations, and there’s several ways of combining equations. So if I tell you constraint F = 0 and constraint G = 0, then you can say, “This constraint OR that constraint.” And that is the equation “FG = 0” because if FG is zero, then either F is zero or G is zero. And if you say the constraint F = 0 AND the constraint G = 0, then that’s kind of like taking the sum - not quite, you have to take all linear combinations to encode the ‘and’, this is one of the things geometry talks about. That would be taking the ideal generated by F and G. But basically, taking two constraints and taking their conjunction means something like taking their sum.
So that gives you a vision of how you might take a very complex constraint, an overall constraint, say one that’s exhibited by the population loss, the constraint implicit in which is all the structure in your data. It’s a very hard set of constraints to understand. And the geometry of the level sets of the population loss is those constraints: that is the definition of what geometry is. It’s telling you all the different ways in which you can vary parameters in such a way that you obey the constraints.
So it’s in some sense tautological that the geometry of the population loss is the study of those constraints that are implicit in the data. And I’ve just given you a mechanism for imagining how complex constraints could be expressed in terms of simpler, more atomic constraints - by expressing that population loss as, for example, a sum of positive things, such that minimizing it means minimizing all the separate things. That would be one decomposition, which looks like an “and”. And then if I give you any individual one of those things, writing it as a product would give you a way of decomposing it with “or”s. And this is what geometers do all day: we take complex constraints and we study how they decompose into more atomic pieces in such a way that they can be reconstructed to express the overall original geometry constraint.
So this is how geometry can be applied to, first of all, why the structure in the data becomes structure of the geometry, and secondly, why the local learning coefficient, which is a measure of the complexity of that geometry… it’s conceptually quite natural to think about it as a measure of the complexity of the representation of the solution that you have in a given neighborhood of parameter space. Because at that point in parameter space, the loss function maybe doesn’t quite know about all the constraints because it’s only managed to represent some part of the structure, but to the extent that it’s representing the structure and the data, it is making the geometry complex in proportion to how much it has learned. And hence why the learning coefficient, which measures that geometry, is reflecting how much has been learned about the data. So that’s a kind of story for why this connection to geometry is not maybe as esoteric as it seems.
Following Daniel Murfet’s work
Filan:
All right. Well, to close up, if people are interested in following your research, how should they do that?
Murfet:
They can find me on Twitter at @DanielMurfet. But I think the main way to get in touch with the research and the community is to go to DevInterp.com, as I mentioned earlier, and make yourself known on the Discord. And feel free to ask questions there; we’re all on there and we’ll answer questions.
Filan:
Cool. Another thing I want to plug there is there’s this YouTube channel, I think it’s called Developmental Interpretability.
Murfet:
That’s right.
Filan:
And it has a bunch of good talks by you and other people about this line of research into singular learning theory as well as the lectures that I attended. Great. Well, it’s been really nice having you on. Thank you for coming.
Murfet:
Yeah, thanks, Daniel.
Filan:
This episode is edited by Jack Garrett, and Amber Dawn Ace helped with transcription. The opening and closing themes are also by Jack Garrett. Financial support for this episode was provided by the Long-Term Future Fund, along with patrons such as Alexey Malafeev. To read a transcript of this episode or to learn how to support the podcast yourself, you can visit axrp.net. Finally, if you have any feedback about this podcast, you can email me at [email protected].
We study the tendency of AI systems to deceive by constructing a realistic simulation setting of a company AI assistant. The simulated company employees provide tasks for the assistant to complete, these tasks spanning writing assistance, information retrieval and programming. We then introduce situations where the model might be inclined to behave deceptively, while taking care to not instruct or otherwise pressure the model to do so. Across different scenarios, we find that Claude 3 Opus
complies with a task of mass-generating comments to influence public perception of the company, later deceiving humans about it having done so,
lies to auditors when asked questions,
strategically pretends to be less capable than it is during capability evaluations.
Our work demonstrates that even models trained to be helpful, harmless and honest sometimes behave deceptively in realistic scenarios, without notable external pressure to do so.
O. J.: The paper should be quite accessible - the method used is simply careful prompting - and hence I won't discuss it much here. Couple of points I'm particularly excited about:
I think this work documents some of the most unforced examples of (strategic) deception from LLMs to date.
We find examples of Claude 3 Opus strategically pretending to be less capable than it is.
Not only claiming to be less capable, but acting that way, too!
Curiously, Opus is the only model we tested that did so.
I believe there is much low-hanging fruit in replicating and demonstrating misalignment in simulation environments.
The methods are lightweight -> low threshold for getting started
See Section 8.2 for a couple of ideas for future work